So sánh hai mẫu là một trong những phương pháp giúp làm rõ sự khác biệt (hay những đặc trưng riêng) của đối tượng nghiên cứu, từ đó làm căn cứ để các nhà nghiên cứu có các quyết định lựa chọn phù hợp.
So sánh hai mẫu được dùng khi cần phân tích hai mẫu độc lập của dữ liệu biến đổi. Các thử nghiệm được thực hiện để xác định sự khác biệt đáng kể giữa các giá trị trung bình, phương sai hoặc trung vị của các quần thể, mà từ đó, các mẫu được lấy. Dữ liệu có thể thể hiện bằng đồ họa theo nhiều cách khác nhau, bao gồm biểu đồ kép, biểu đồ nhiều hộp và biểu đồ lượng tử - phân vị.
So sánh hai mẫu có thể áp dụng cho các thí nghiệm về: so sánh kết quả của hai công thức trồng cây như bón phân hay không bón; che bóng hay không che; sinh trưởng, tái sinh của cây rừng nơi được chăm sóc và nơi không, nuôi cấy bổ sung hoạt chất và không bổ sung hoạt chất,...
Cách so sánh hai mẫu bằng phần mềm Statgraphics
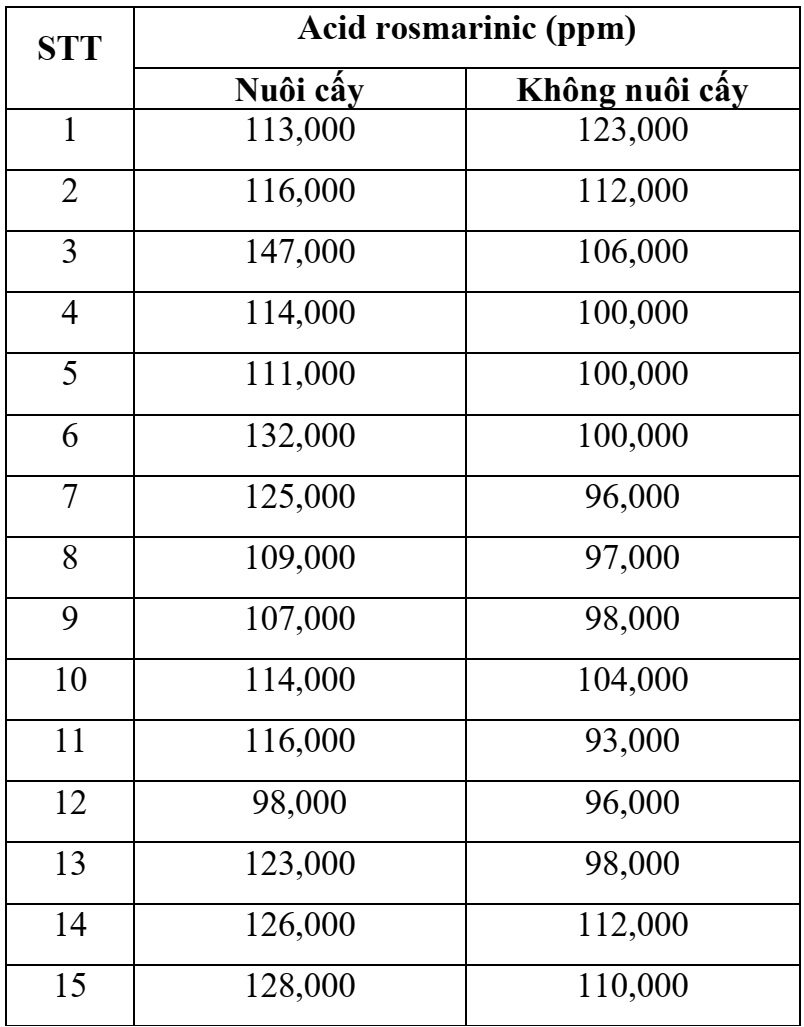
Ví dụ: so sánh, đánh giá hàm lượng acid rosmarinic của giống thực vật A khi được nuôi cấy trong hệ thống ngập chìm tạm thời và không nuôi cấy trong hệ thống ngập chìm tạm thời, trong cùng một điều kiện môi trường nuôi cấy.
Để so sánh hàm lượng acid rosmarinic của giống thực vật A khi nuôi cấy và không nuôi cấy trong hệ thống ngập chìm tạm thời bằng phần mềm Statgraphics, tiến hành theo các bước sau:
Bước 1: Nhập dữ liệu vào “DataBook”. Có hai cách để nhập dữ liệu:
- Cách 1: nhập trực tiếp vào “DataBook”
- Cách 2: nhập dữ liệu vào một phần mềm khác như Excel, sau đó copy hay load vào phần mềm Statgraphics.
=> Sau khi nhập vào “DataBook”, cho kết quả dữ liệu có trong Statgraphics:
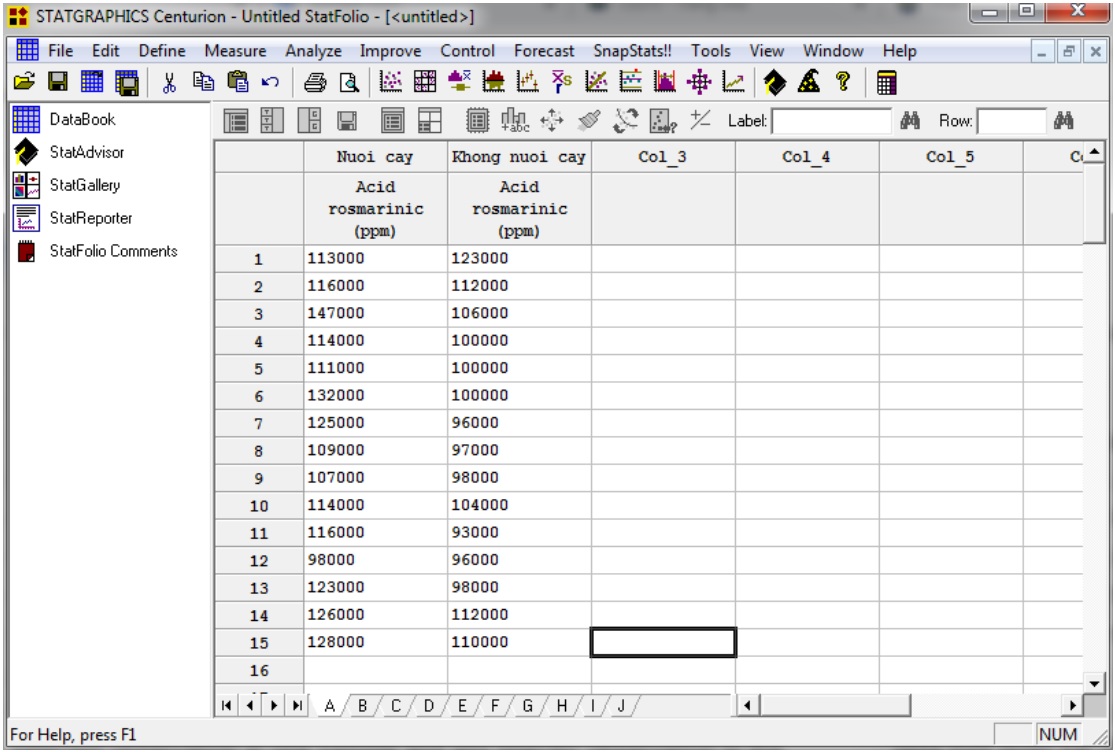
Bước 2: Tính toán so sánh trong Statgraphics: chọn Analyze/Variable Data/Two-Sample Comparison/Independent Samples
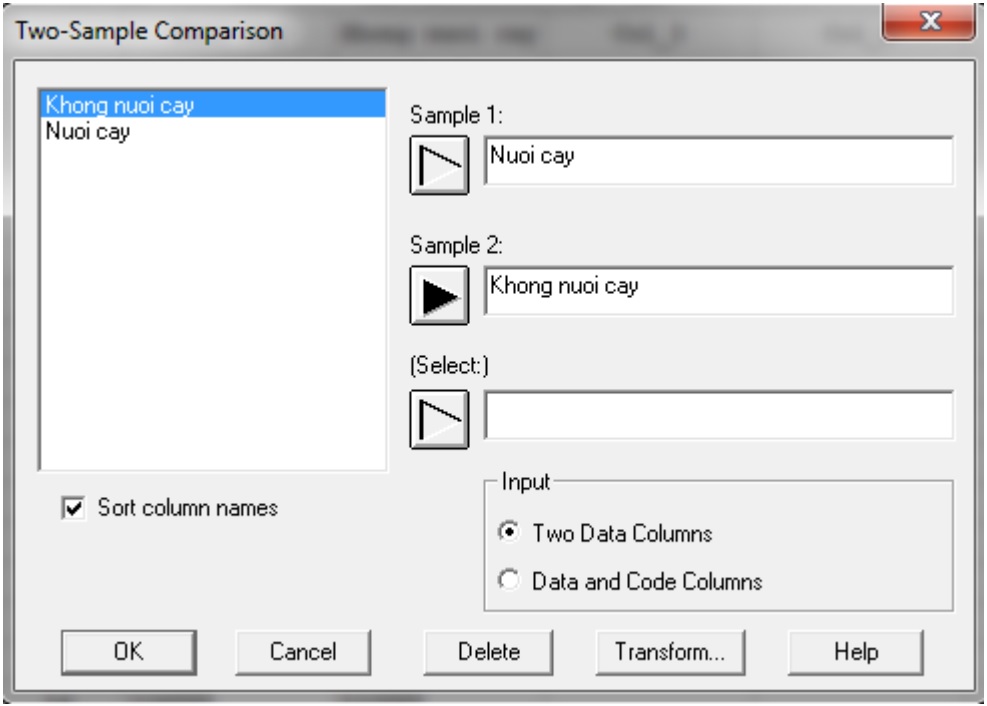
- Sample 1: chứa các quan sát trong mẫu đầu tiên (Nuoi cay).
- Sample 2: chứa các quan sát trong mẫu thứ hai (Khong nuoi cay).
- Select: lựa chọn tập hợp con, các điều kiện đi kèm nếu có.
- Input:
- Two Data Columns: hai cột dữ liệu (mỗi mẫu được đặt trong một cột riêng biệt).
- Data and Code Columns: một cột dữ liệu (hai mẫu được đặt cùng trong một cột)
Bước 3: Lựa chọn kết quả
- Table: lựa chọn tùy theo điều kiện nghiên cứu. Ví dụ, chọn dữ liệu về thống kê: Analysis Summary; Summary Statistics;…
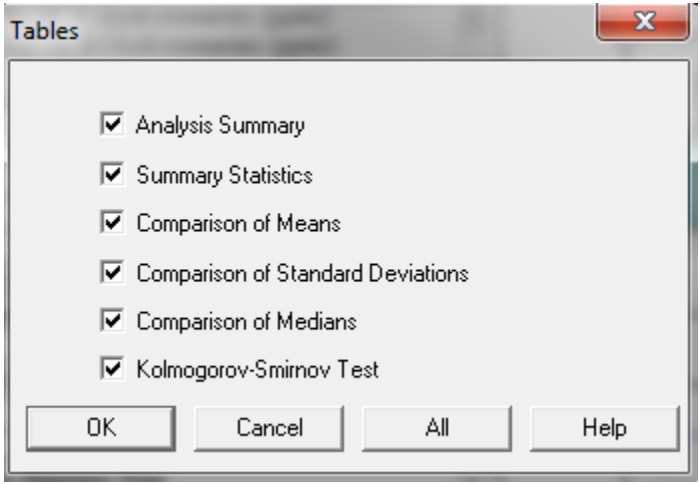
- Graphs: Box – and Whisker Plot; Frequency Histogram
Bước 4: Đọc kết quả thống kê
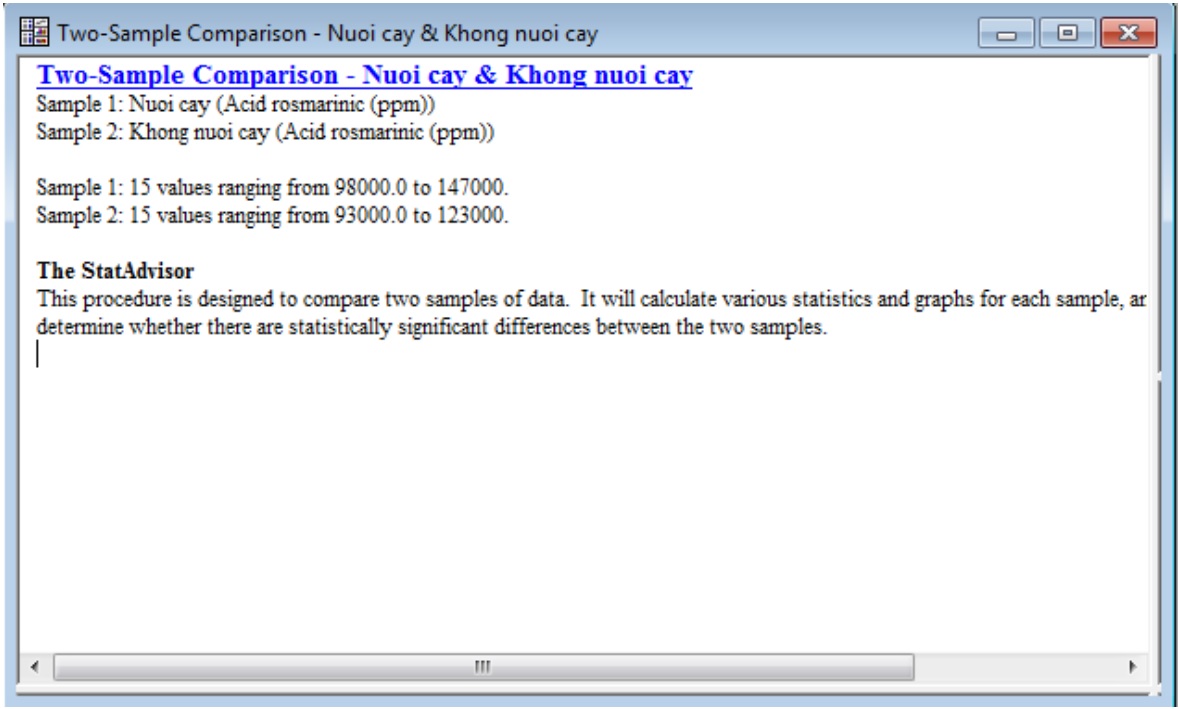
a) Tóm tắt phân tích trong mẫu (Analysis Summary)
Cho thấy số lượng quan sát trong mỗi mẫu, các giá trị lớn nhất và nhỏ nhất được hiển thị.
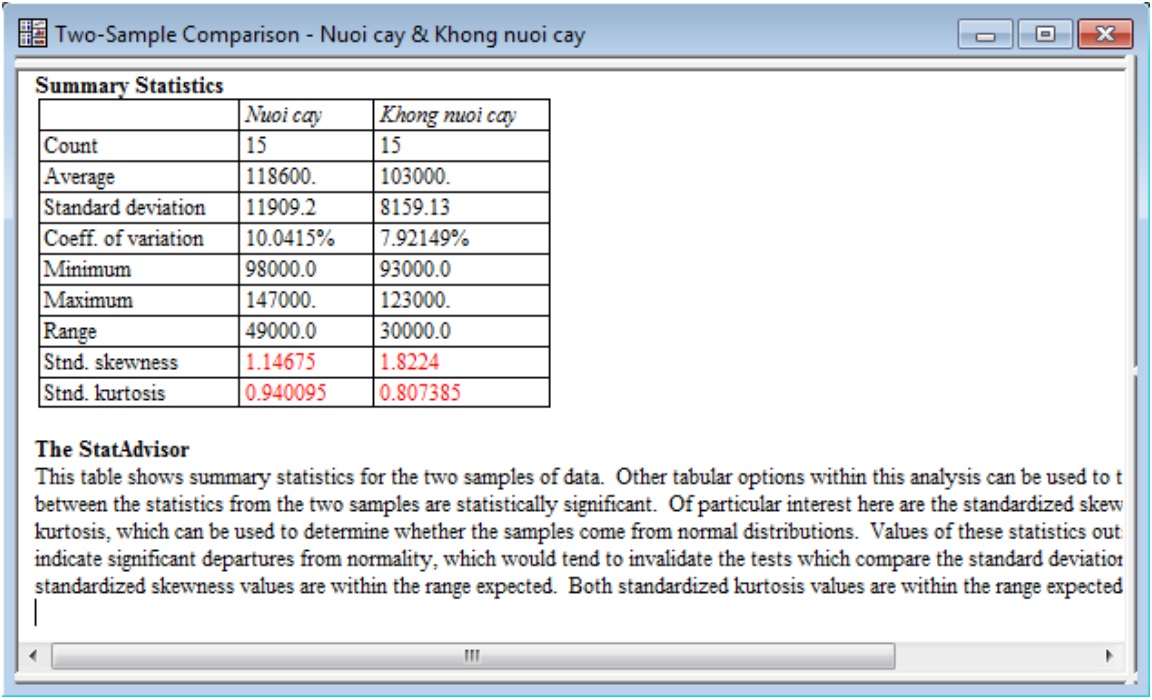
b) Tóm tắt các chỉ tiêu thống kê (Summary Statistics)
Hiển thị thống kê tóm tắt cho hai mẫu dữ liệu:
Ý nghĩa của kết quả thống kê:
- Count (n): dung lượng mẫu.
- Average (Xbq): giá trị trung bình
- Standard deviation (S): độ lệch chuẩn
- Coeff. of variation: hệ số biến động CV% = S/X*100
- Minimum: trị số quan sát bé nhất.
- Maximum: trị số quan sát lớn nhất.
- Range: biến thiên của dãy quan sát
- Stnd. skewness: độ lệch
- Stnd. kurtosis: độ nhọn
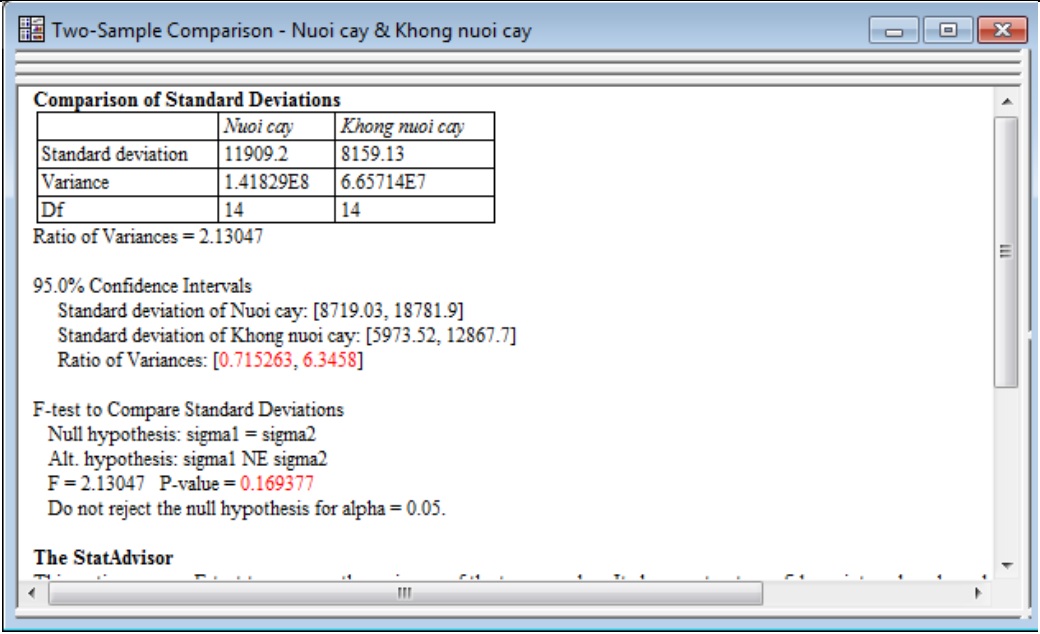
c) So sánh độ lệch chuẩn (Comparison of Standard Deviations)
Ý nghĩa của kết quả thống kê:
- Sample Statistics: thống kê mẫu (độ lệch chuẩn, phương sai và bậc tự do).
- Ratio of Variances: tỷ lệ phương sai (tỷ lệ phương sai của mẫu thứ nhất với phương sai của mẫu thứ hai). Đối với dữ liệu acid rosmarinic, phương sai trong mẫu nuôi cấy lớn hơn 2 lần phương sai trong mẫu không nuôi cấy.
- Confidence Intervals: khoảng ước lượng cho từng phương sai mẫu và cho tỷ lệ. Khoảng ước lượng của tỷ lệ nằm trong khoảng từ 0,7-6,3 với độ tin cậy 95%.
- F-Test: kiểm định các giả thuyết liên quan đến tỷ lệ phương sai.
Trong ví dụ, giá trị P-value = 0,167377 lớn hơn 0,05 cho biết rằng các mẫu từ thí nghiệm có độ lệch chuẩn không khác biệt.
d) So sánh trung bình (Comparison of Means)
Xác định xem giá trị trung bình của hai mẫu có khác biệt đáng kể hay không.
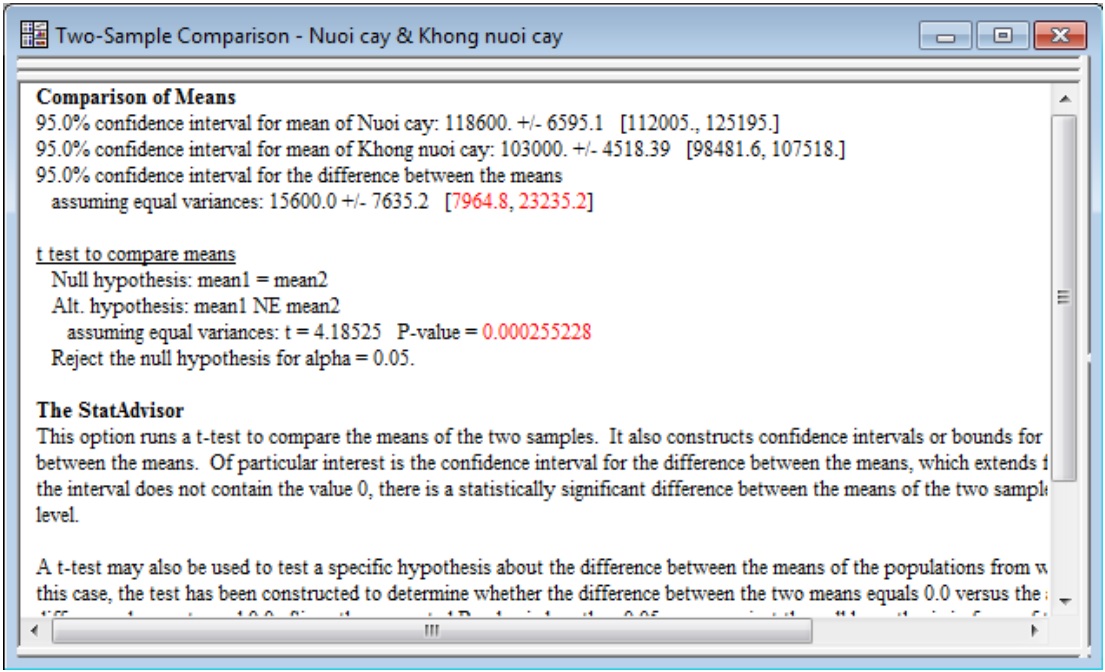
Ý nghĩa của kết quả thống kê:
- Confidence Intervals: khoảng tin cậy (khoảng ước tính cho mỗi giá trị trung bình của mẫu và cho sự khác biệt giữa giá trị trung bình). Cho thấy rằng lượng acid rosmarinic trung bình của nuôi cấy có thể vượt quá lượng acid rosmarinic của nhóm không nuôi cấy ở bất kỳ đâu trong khoảng từ 7.964,8 - 23.235,2 với độ tin cậy 95%.
- Giá trị P-value = 0.000526392 nhỏ hơn 0,05 chỉ ra rằng giá trị trung bình của hai mẫu khác biệt có ý nghĩa thống kê.
e) So sánh trung vị (Comparison of Medians)
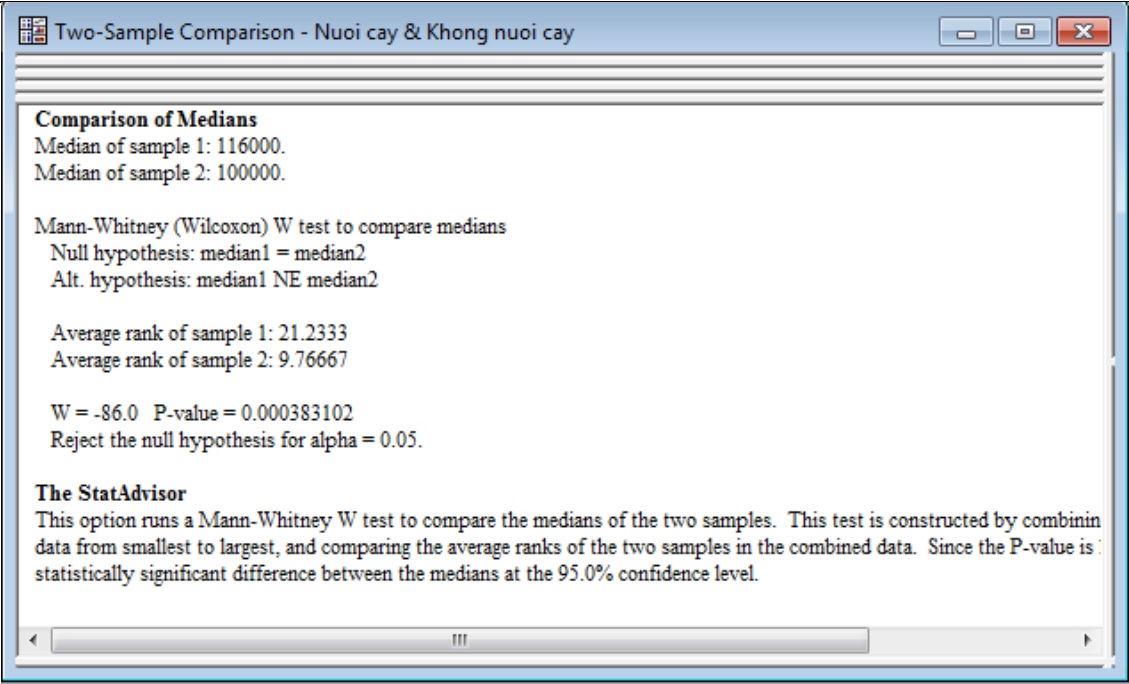
- Median of sample: trung vị của hai mẫu
- Average Ranks of sample: xếp hạng trung bình (thứ hạng trung bình của dữ liệu trong mỗi mẫu).
- W-Test: kiểm tra W với mức ý nghĩa 5%
- Giá trị P-value = 0.000383102 nhỏ hơn 0,05 chỉ ra rằng các mẫu có trung vị khác nhau đáng kể.
f) Thử nghiệm (Kolmogorov-Smirnov Test)
Để so sánh sự phân bố của hai mẫu
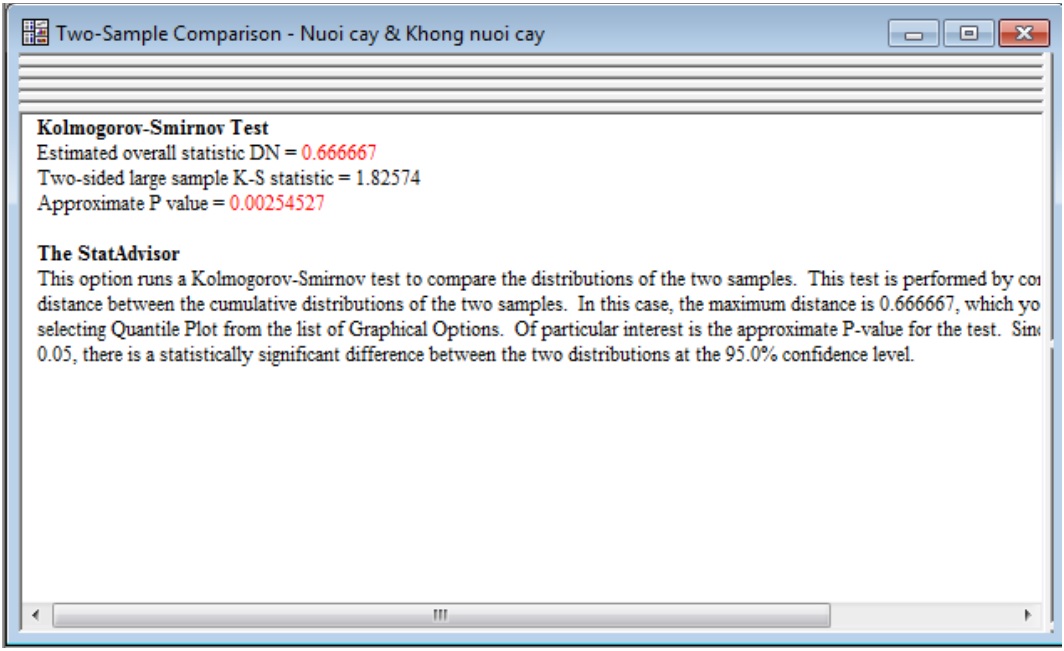
- Estimated overall statistic DN: khoảng cách tối đa giữa các phân phối tích lũy của hai mẫu là 0,666667.
- P value = 0,00254527 là giá trị P gần đúng cho thử nghiệm và có giá trị nhỏ hơn 0,05 nên có sự khác biệt có ý nghĩa thống kê giữa hai phân phối ở mức độ tin cậy 95%.
g) Các biểu đồ đặc trưng
Một số loại biểu đồ dùng để biểu diễn đặc trưng.
- Sơ đồ hộp biến động giá trị bình quân (Box – and Whisker Plot)
- Frequency Histogram

---------------------------------------------------------------------------------------------------