Giới thiệu
Trước khi phân tích bộ dữ liệu nào đó thì bộ dữ liệu đó cần được làm sạch, nghĩa là, bộ dữ liệu phải thực thi được các lệnh, vì vậy chúng ta phải thực hiện giai đoạn “tiền xử lý” trước khi phân tích dữ liệu. Tiền xử lý dữ liệu thông thường bao gồm các bước sau đây
• Đọc tập dữ liệu
• Khai phá dữ liệu
• Làm sạch dữ liệu
• Xử lý dữ liệu khuyết
• Chuẩn hóa dữ liệu
• Xử lý các giá trị ngoại lai
Dataset
Chúng ta xem xét bộ dữ liệu Expanded_data_with_more_features; bộ dữ liệu này bao gồm điểm số từ ba bài kiểm tra của học sinh tại trường và nhiều yếu tố khác có thể tác động lên chúng. Bộ dữ liệu bao gồm các thuộc tính sau đây
• Gender: Giới tính (male/female)
• EthnicGroup: Nhóm sắc tộc của học sinh
• ParentEduc: Trình độ học vấn của bố mẹ (trung học đến sau đại học)
• LunchType: Loại bữa trưa ở trường (tiêu chuẩn hoặc miễn phí/giảm giá)
• TestPrep: Khóa học chuẩn bị kiểm tra (hoàn thành hoặc chưa hoàn thành)
• ParentMaritalStatus: Tình trạng hôn nhân của bố mẹ (married/single/widowed/divorced)
• PracticeSport: Hoạt động thể chất (never/sometimes/regularly)
• IsFirstChild: Con đầu lòng trong gia đình? (yes/no)
• NrSiblings: Số lượng anh chị em trong gia đình (0 đến 7)
• TransportMeans: Phương tiện giao thông đến trường (schoolbus/private)
• WklyStudyHours: Số giờ tự học hàng tuần (< 5; 5 - 10; > 10)
• MathScore: Điểm toán (0-100)
• ReadingScore: Điểm kiểm tra đọc hiểu (0-100)
• WritingScore: Điểm thi viết (0-100)
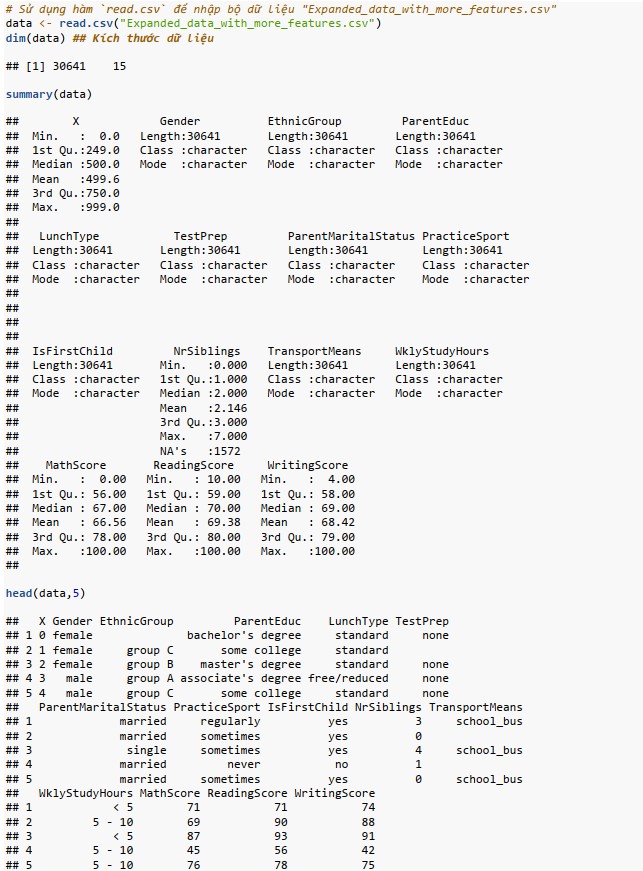
Đọc tập dữ liệu
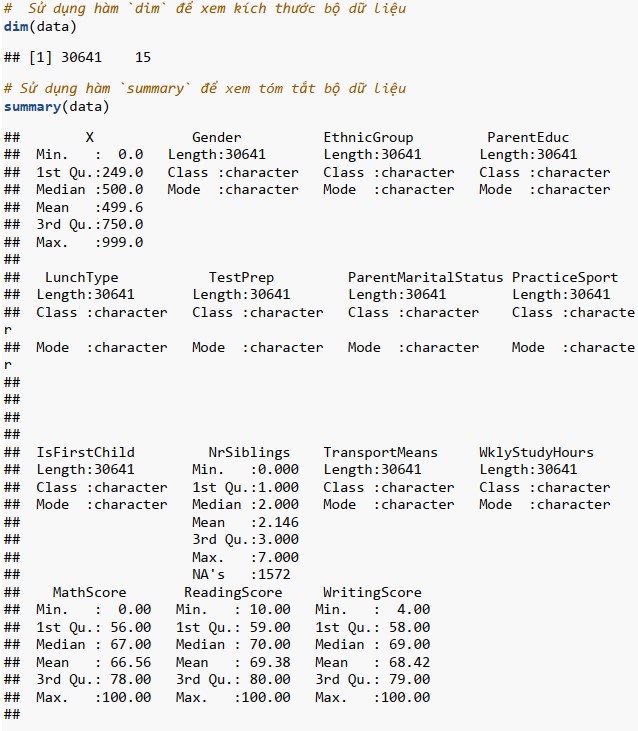
Khai phá dữ liệu
Mục tiêu của khai phá dữ liệu là để hiểu cấu trúc bên trong của dữ liệu; ví dụ như số lượng mẫu, thuộc tính, định dạng của thuộc tính, mối quan hệ của các thuộc tính, ….
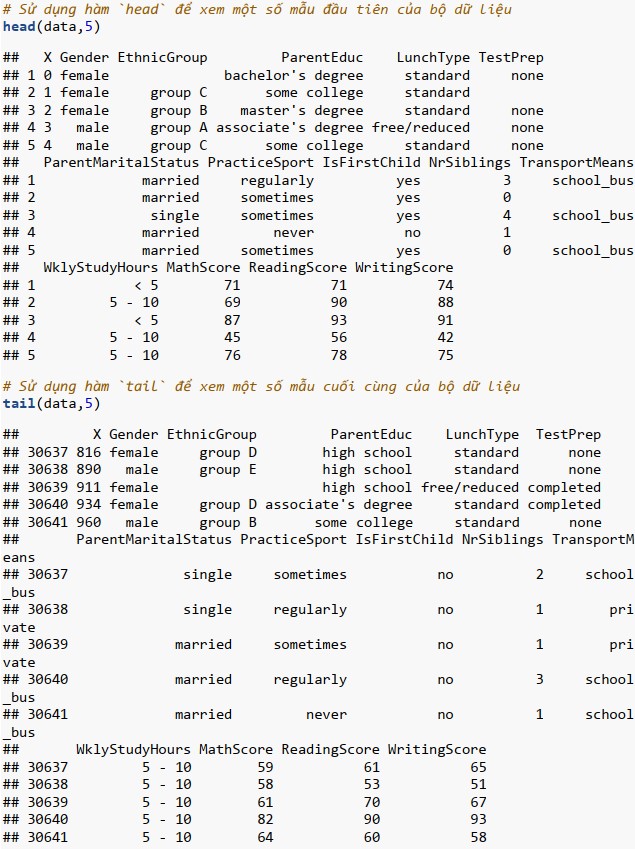
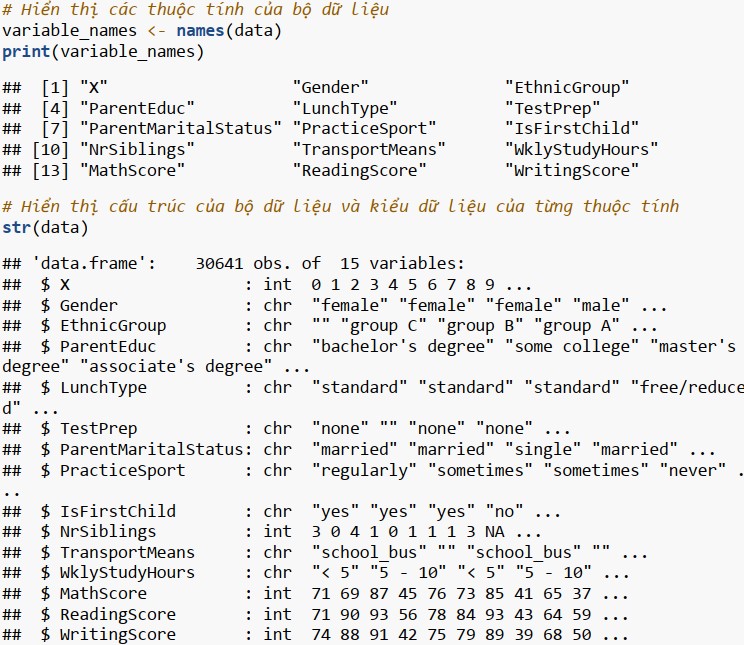
Làm sạch và định dạng lại dữ liệu

Xử lý dữ liệu khuyết
Liêt kê dữ liệu khuyết
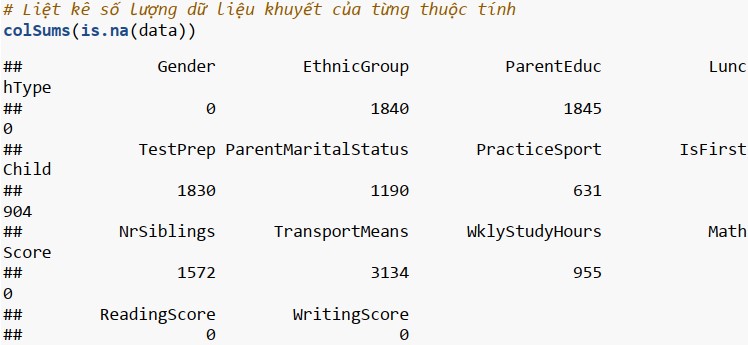
Xử lý dữ liệu khuyết cho từng thuộc tính

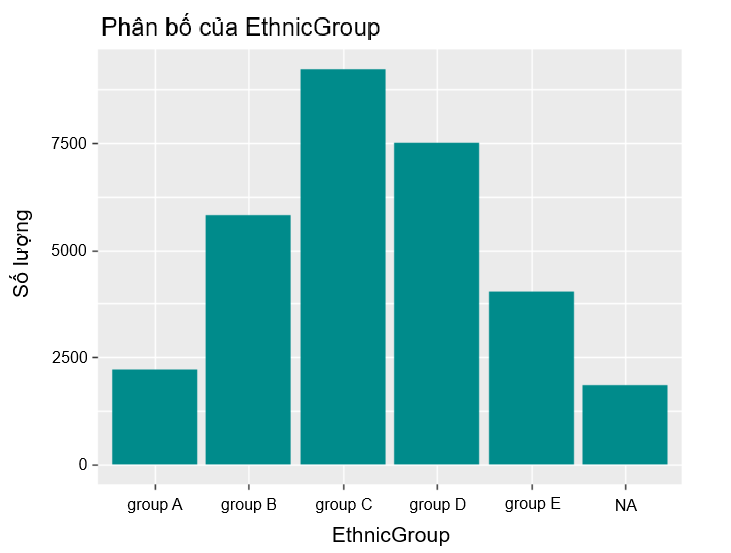
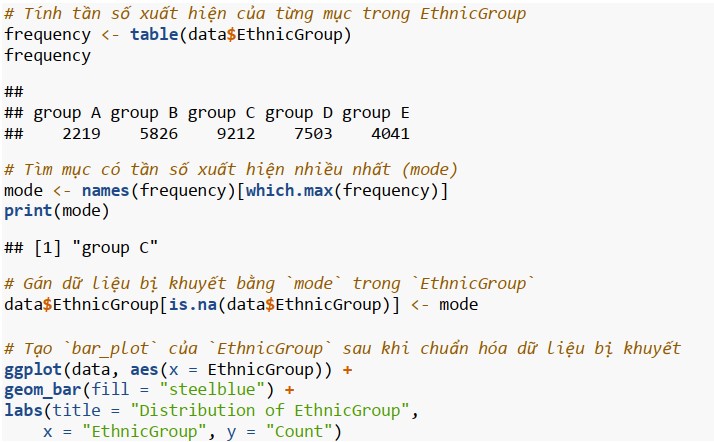

Sau khi chuẩn hóa thuộc tính EthnicGroup, chúng ta sẽ chuẩn hóa các thuộc tính ParentEduc, WklyStudyHours và NrSiblings theo những cách khác nhau; dựa trên đặc trưng của thuộc tính đó.

Tiếp đến, chúng ta sẽ xử lý dữ liệu khuyết cho các thuộc tính còn lại TransportMeans, IsFirstChild, TestPrep, ParentMaritalStatus và PracticeSport

Cuối cùng, chúng ta hãy kiểm tra xem có giá trị nào bị khuyết trong bộ dữ liệu hay không.
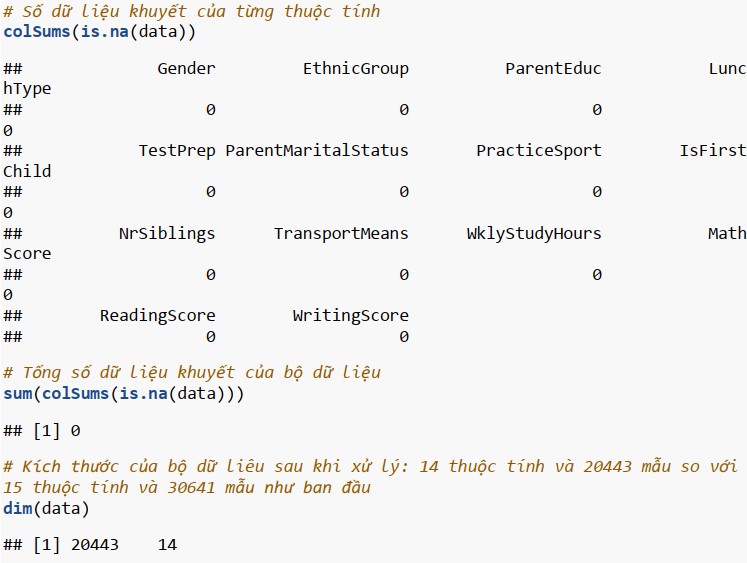
Chuẩn hóa dữ liệu
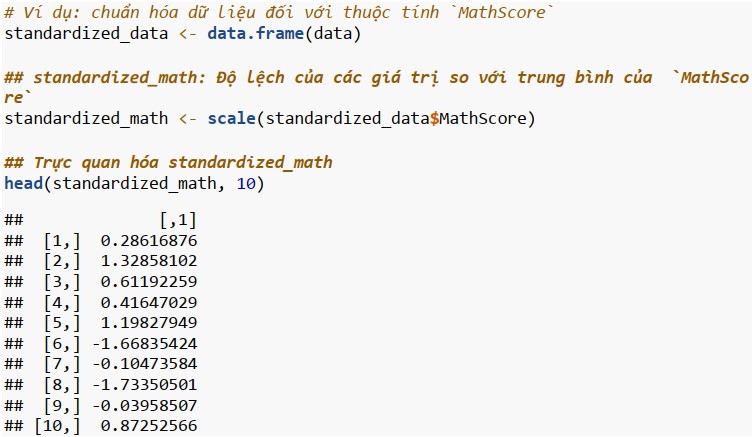
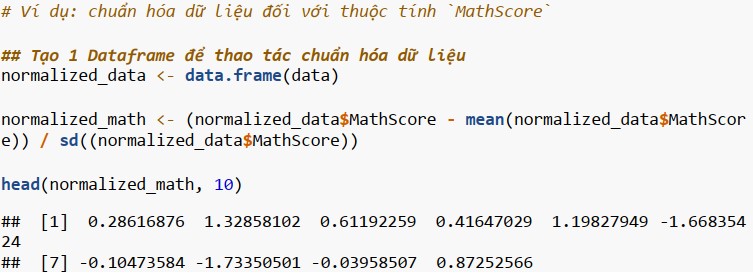
Chúng ta có các thuộc tính khác nhau trong tập dữ liệu với các thang đo khác nhau. Việc chuẩn hóa là cần thiết để phục vụ cho vệc sử dụng các thuật toán trong phân tích. Có nhiều phương pháp khác nhau; chẳng hạn như, chuẩn hóa tỷ lệ thập phân, chuẩn hóa Min-Max, chuẩn hóa định chuẩn (Gauss). Trong số này thì chuẩn hóa định chuẩn là phổ biến nhất; chuẩn hóa mà giá trị trung bình của từng thuộc tính bằng 0 và độ lệch chuẩn của từng thuộc tính bằng 1.
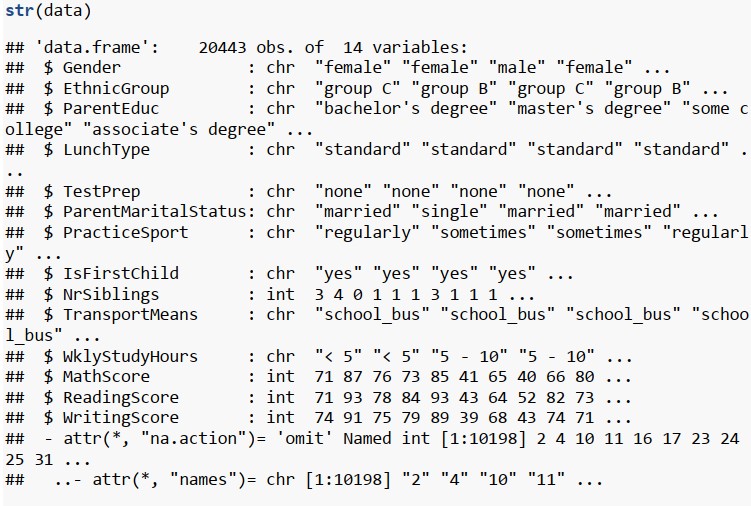
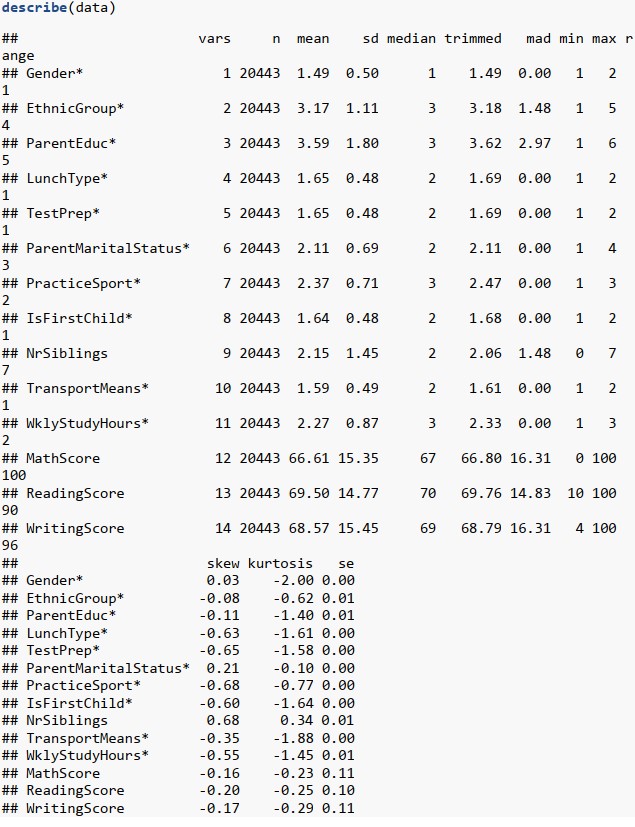
Đầu tiên ta sử dụng hàm str và describe để nắm bắt được cấu trúc và đại lượng thống kê trong từng thuộc tính.
Feature scaling
Standardization
Feature Encoding
Feature Encoding là một kỹ thuật để chuyển đổi dữ liệu của thuộc tính phân loại hoặc không phải số thành số. Ví dụ như Gender, EthnicGroup, ParentEduc, LunchType, ParentMaritalStatus, PracticeSport, IsFirstChild, TransportMeans, WklyStudyHours.
One Hot Encoding
One Hot Encoding là phương pháp chuyển đổi các thuộc tính phân loại thành định dạng nhị phân. Nó tạo ra các cột nhị phân mới (0 và 1) cho mỗi danh mục trong thuộc tính gốc. Mỗi danh mục trong cột gốc được biểu diễn dưới dạng một cột riêng biệt, trong đó giá trị 1 biểu thị sự hiện diện của danh mục đó và 0 biểu thị sự vắng mặt của danh mục đó. One Hot Encoding giúp loại bỏ tính thứ tự của dữ liệu, cải thiện hiệu suất mô hình học máy, khả năng tương thích với thuật toán yêu cầu đầu vào là số.
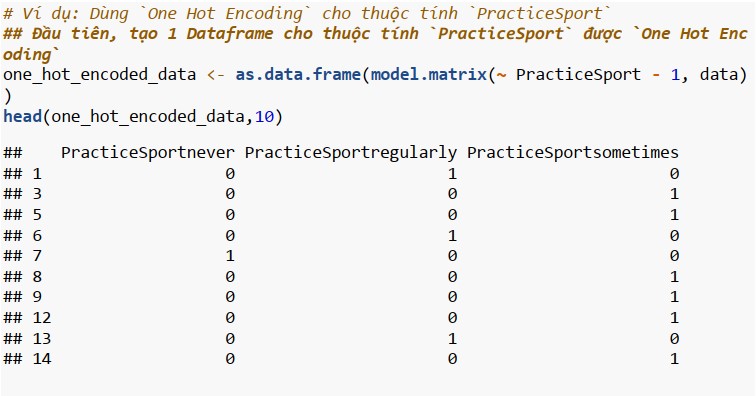
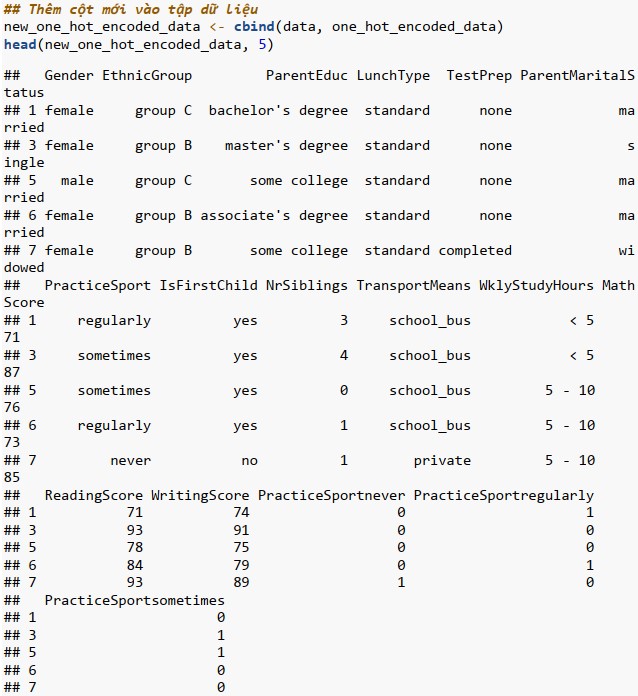
Ordinal encoding
Ordinal encoding được sử dụng để biểu diễn các thuộc tính phân loại có mối quan hệ theo thứ tự hoặc phân cấp bằng cách sử dụng các giá trị số.

Xử lý các giá trị ngoại lai
Sử dụng biểu đồ Box Plots để trực quan hóa mật độ tập trung của dữ liệu của từng thuộc tính mà danh mục có giá trị số.

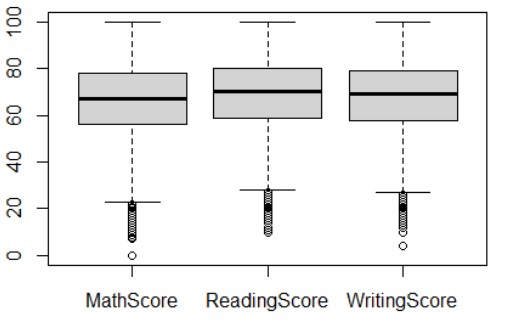
Tiếp theo, chúng ta tiến hành loại bỏ các giá trị ngoại lai trên điều kiện cho trước.


Kết Luận
Tiền xử lý dữ liệu là một quy trình rất phức tạp, quy trình xử lý còn tùy thuộc vào từng bộ dữ liệu. Vì vậy, việc nắm vững nền tảng trong quy trình tiền xử lý dữ liệu là cực kỳ quan trọng trong phân tích dữ liệu
Nhất Luận
----------------------------------------
Tài liệu tham khảo:
[1] Expanded_data_with_more_features.csv. https://www.kaggle.com/datasets/desalegngeb/students-exam-scores
[2] airqualityES: Air Quality Measurements in Spain from 2011 to 2018. https://cran.r-project.org/web/packages/airqualityES/index.html
[3] Data Preprocessing in R. https://www.geeksforgeeks.org/data-preprocessing-in-r/?ref=header_outind
[4] Data Wrangling (Data Preprocessing). https://rpubs.com/prtk/900512
[5] Encoding Categorical Data in R. https://www.geeksforgeeks.org/encoding-categorical-data-in-r/
[6] One Hot Encoding in Machine Learning. https://www.geeksforgeeks.org/ml-one-hot-encoding/
[7] encoding dataset. https://github.com/SarangPratap/Dataset
[8]Guided Ordinal Encoding Techniques. https://www.geeksforgeeks.org/guided-ordinal-encoding-techniques/
[9]Box plot in R using ggplot2. https://www.geeksforgeeks.org/box-plot-in-r-using-ggplot2/