Làm sạch dữ liệu là một bước quan trọng trong quy trình xử lý và phân tích dữ liệu, đó là việc xác định và loại bỏ các dữ liệu bị khuyết, trùng lặp hoặc không liên quan. Mục tiêu của việc làm sạch dữ liệu là để đảm bảo dữ liệu chính xác, nhất quán và không có lỗi, giúp quá trình phân tích dữ liệu được chính xác. Vì vậy các nhà khoa học dữ liệu thường đầu tư rất nhiều thời gian cho bước này, vì “Dữ liệu tốt còn hơn các thuật toán tốt”.
Đặc trưng của tập dữ liệu
Một tập dữ liệu luôn có một trong hai đặc điểm: dữ liệu sạch hoặc dữ liệu lộn xộn.
Đặc trưng của dữ liệu sạch
Các đặc điểm của dữ liệu sạch:
- Không có hàng, giá trị trùng lặp
- Không có lỗi chính tả
- Không có ký tự đặc biệt
- Kiểu dữ liệu tương thích để phân tích
- Giá trị ngoại lại được quản lý
- Cấu trúc dữ liệu tinh gọn
Đăc trưng của dữ liệu lộn xộn
Dữ liệu lộn xộn có các đặc điểm như sau:
- Các ký tự đặc biệt (ví dụ như có chữ trong các giá trị số)
- Giá trị số được lưu trữ dưới dạng dữ liệu văn bản, ký tự
- Dòng trùng lặp
- Lỗi chính tả
- Khoảng trắng
- Thiếu dữ liệu
- Dữ liệu không chính xác
Các bước làm sạch dữ liệu
Làm sạch dữ liệu là quy trình có hệ thống để xác định và sửa lỗi, sự không nhất quán và không chính xác trong một tập dữ liệu. Các bước thiết yếu để thực hiện việc làm sạch dữ liệu như sau:
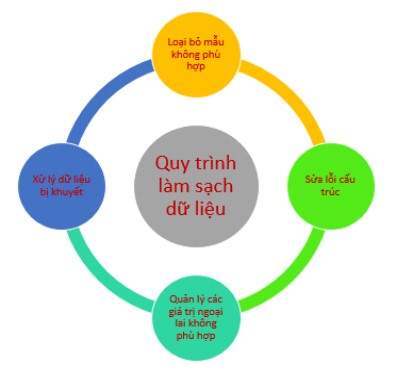
• Loại bỏ các mẫu không phù hợp: xác định và loại bỏ các mẫu không liên quan hoặc dư thừa khỏi tập dữ liệu. Bước này bao gồm việc kiểm tra kỹ lưỡng các thuộc tính nhập dữ liệu để tìm các mẫu trùng lặp, thông tin không liên quan hoặc các điểm dữ liệu không đóng góp có ý nghĩa cho phân tích. Việc loại bỏ các mẫu không phù hợp sẽ giúp hợp lý hóa tập dữ liệu, giảm nhiễu và cải thiện chất lượng tổng thể.
• Sửa lỗi cấu trúc: xử lý các vấn đề về cấu trúc trong tập dữ liệu, chẳng hạn như sự không nhất quán trong định dạng dữ liệu, quy ước đặt tên hoặc loại biến. Chuẩn hóa định dạng, sửa lỗi đặt tên và đảm bảo tính thống nhất trong biểu diễn dữ liệu. Sửa lỗi cấu trúc giúp tăng cường tính nhất quán của dữ liệu và tạo điều kiện cho việc phân tích và diễn giải chính xác.
• Quản lý các giá trị ngoại lai không phù hợp: xác định và quản lý các giá trị ngoại lai (các điểm dữ liệu lệch đáng kể so với tổng thể). Tùy thuộc vào ngữ cảnh, việc loại bỏ các giá trị ngoại lai hay chuyển đổi chúng để giảm thiểu tác động của chúng đối với quá trình phân tích là rất quan trọng.
• Xử lý dữ liệu bị khuyết: đưa ra phương pháp để xử lý dữ liệu bị khuyết dựa trên đặc trưng của bộ dữ liệu. Điều này có thể bao gồm việc đưa ra các giá trị bị khuyết dựa trên các phương pháp thống kê, xóa mẫu có giá trị bị khuyết hoặc gán bằng một giá trị nào đó; ví dụ như, trung bình, max, min,… Xử lý dữ liệu bị khuyết nhằm đảm bảo một tập dữ liệu mới hoàn chỉnh hơn và đảm bảo tính toàn vẹn trong phân tích.
Làm sạch tập dữ liệu “airquality”
Xét tập dữ liệu “airquality”

Tập dữ liệu “airquality” bao gồm 153 mẫu và 6 thuộc tính.
- Ozone: nồng độ trung bình ozon
- Solar.R: bức xạ mặt trời trong dải tần số 4.000 – 7.700 Angstrom
- Wind: tốc độ gió trung bình (dặm/giờ)
- Temp: nhiệt độ tối đa trong ngày tính theo độ F
- Month: tháng đo đạc
- Day: ngày đo đạc
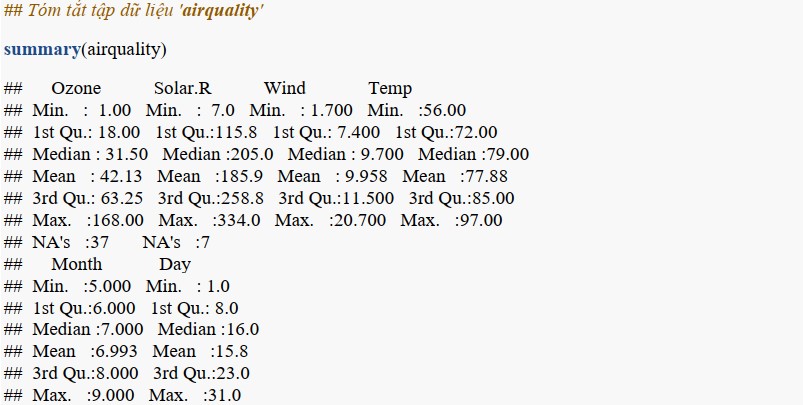
Từ bảng tóm tắt cho thấy thuộc tính Ozone có 37 NA (được gọi là giá trị không xác định hay dữ liệu khuyết) và thuộc tính Solar.R có 7 NA.
Có hai phương pháp xử lý các dữ liệu khuyết cho từng thuộc tính là xóa các mẫu chứa dữ liệu khuyết hoặc thay thế dữ liệu khuyết bằng một giá trị cụ thể nào đó. Phương pháp thứ nhất làm cho kích thước tập dữ liệu giảm và khó kiểm soát khi tập dữ liệu có nhiều thuộc tính và nhiều thuộc tính trong đó bị khuyết dữ liệu. Phương pháp thứ nhì giữ nguyên được kích thước tập dữ liệu, giá trị thay thế có thể là giá trị nhỏ nhất, giá trị nhỏ nhất, tần suất xuất hiện nhiều nhất, giá trị trung bình,…. Đối với các thuộc tính số thì giá trị trung bình của thuộc tính được dùng để thay thế các mục bị khuyết dữ liệu là cách làm phổ biến nhất.
Xử lý dữ liệu khuyết cho hai thuộc tính Ozone và Solar.R bằng phương pháp thay các mục NA bằng giá trị trung bình của thuộc tính đó.

Kết quả cho biết rằng không thể thực hiện phép tính khi thuộc tính có mục NA, vì vậy cần phải bỏ qua mục NA khi thực hiện tính toán.

Tiếp theo, tạo tập dữ liệu mới bằng cách thay thế các mục NA của hai thuộc tính Ozone và Solar.R bằng giá trị trung bình của nó.
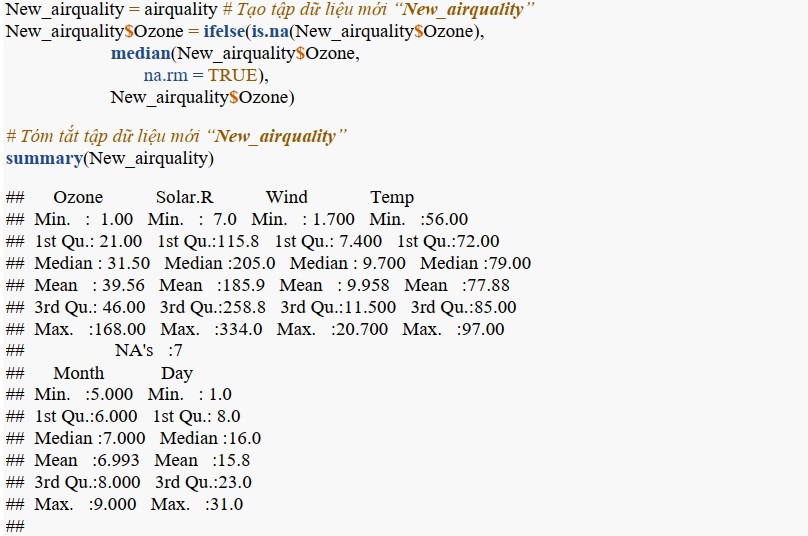
Bảng tóm tắt cho thấy thuộc tính Ozone không còn mục NA. Tập dữ liệu mới chỉ còn thuộc tính Solar.R có các mục NA. Việc thay thế các mục NA trong thuộc tính Solar.R thì thực hiện tương tự như cách làm cho thuộc tính Ozone.
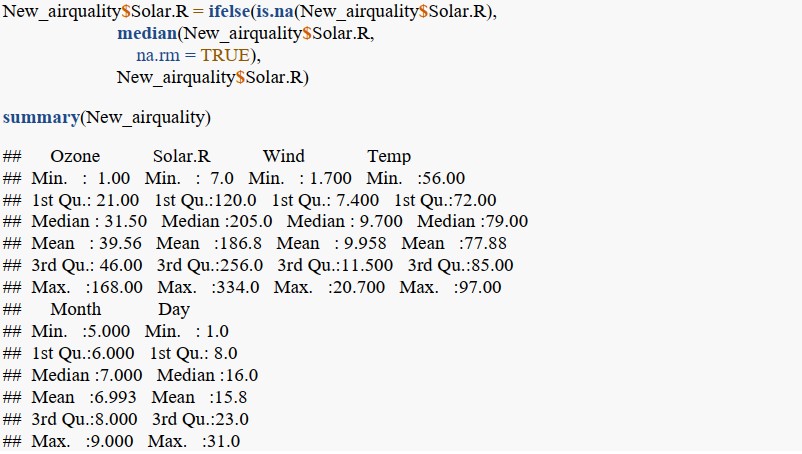
Bảng tóm tắt đã cho thấy tập dữ liệu mới không còn thuộc tính nào có mục NA.
Tiếp theo, quan sát tập dữ liệu mới bằng biểu đồ hộp (box plot) để xem miền giá trị ngoại lai của các thuộc tính.

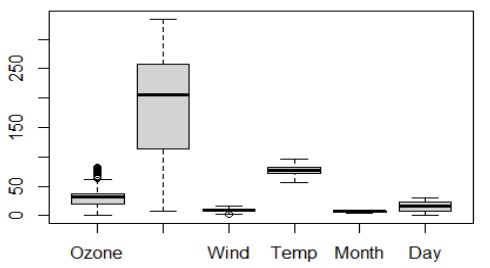
Biểu đồ hộp cho thấy, chỉ có một số giá trị ngoại lai của thuộc tính Ozone và một giá trị ngoại lại của thuộc tính Wind, nhưng miền giá trị của các ngoại lai này nằm không xa miền dữ liệu tập trung. Vì vậy, có thể giữ lại các mẫu chứa giá trị ngoại lai này, hoàn tất giai đoạn làm sạch dữ liệu.
Kết luận
Sau khi làm sạch dữ liệu, tập dữ liệu có thể tính toán được, với độ tin cậy cao hơn, giúp cho công tác xử lý và phân tích chính xác hơn.
Nhất Luận
----------------------------------------
Tài liệu tham khảo:
[1] airqualityES: Air Quality Measurements in Spain from 2011 to 2018. https://cran.r-project.org/web/packages/airqualityES/index.html
[2] Cleaning Data in R. https://rpubs.com/odenipinedo/cleaning-data-in-R
[3] Overview of Data Cleaning. https://www.geeksforgeeks.org/data-cleansing-introduction/?ref=header_outind
[4] Data Cleaning & Transformation with Dplyr in R. https://www.geeksforgeeks.org/data-cleaning-transformation-with-dplyr-in-r/?ref=header_outind