R có kho lưu trữ lớn các gói - là cách tích hợp để sắp xếp và chia sẻ. Thông thường, một gói sẽ bao gồm: mã, tài liệu cho gói và các chức năng bên trong, một số bài kiểm tra để kiểm tra các hoạt động như mong muốn và các tập dữ liệu. Các gói trong R là tập hợp các hàm, mã biên dịch và dữ liệu mẫu và được lưu trữ trong một thư viện. Mặc định, R cài đặt một nhóm các gói trong quá trình cài đặt. Khi khởi động bảng điều khiển R, chỉ có các gói mặc định khả dụng như mặc định. Các gói đã được cài đặt khác cần phải được tải để chương trình R sử dụng khi chạy chúng.
Các gói trong R được lưu trữ trong các kho lưu trữ: CRAN là kho lưu trữ chính thức; Bioconductor là kho lưu trữ theo chủ đề, dành cho phần mềm nguồn mở cho tin sinh học; Github là kho lưu trữ phổ biến nhất cho các dự án nguồn mở, không gian không giới hạn cho nguồn mở, tích hợp với git, phần mềm kiểm soát phiên bản và dễ dàng chia sẻ và cộng tác với người khác.
Một số gói phổ biến và được sử dụng nhiều trong R là: tidyr, ggplot2, ggraph, dplyr, tidyquant, dygraphs, leaflet, ggmap, glue, shiny, plotly, tidytext, stringr, reshape2, dichromat, digest, MASS, caret, e1071, sentiment.
Gói tidyr
Gói tidyr được sử dụng để đơn giản hóa quy trình tạo dữ liệu thông qua các hàm gather(), separate(), unite(), spread(), nest(), unnest(), fill(), full_seq(), drop_na(), replace_na().
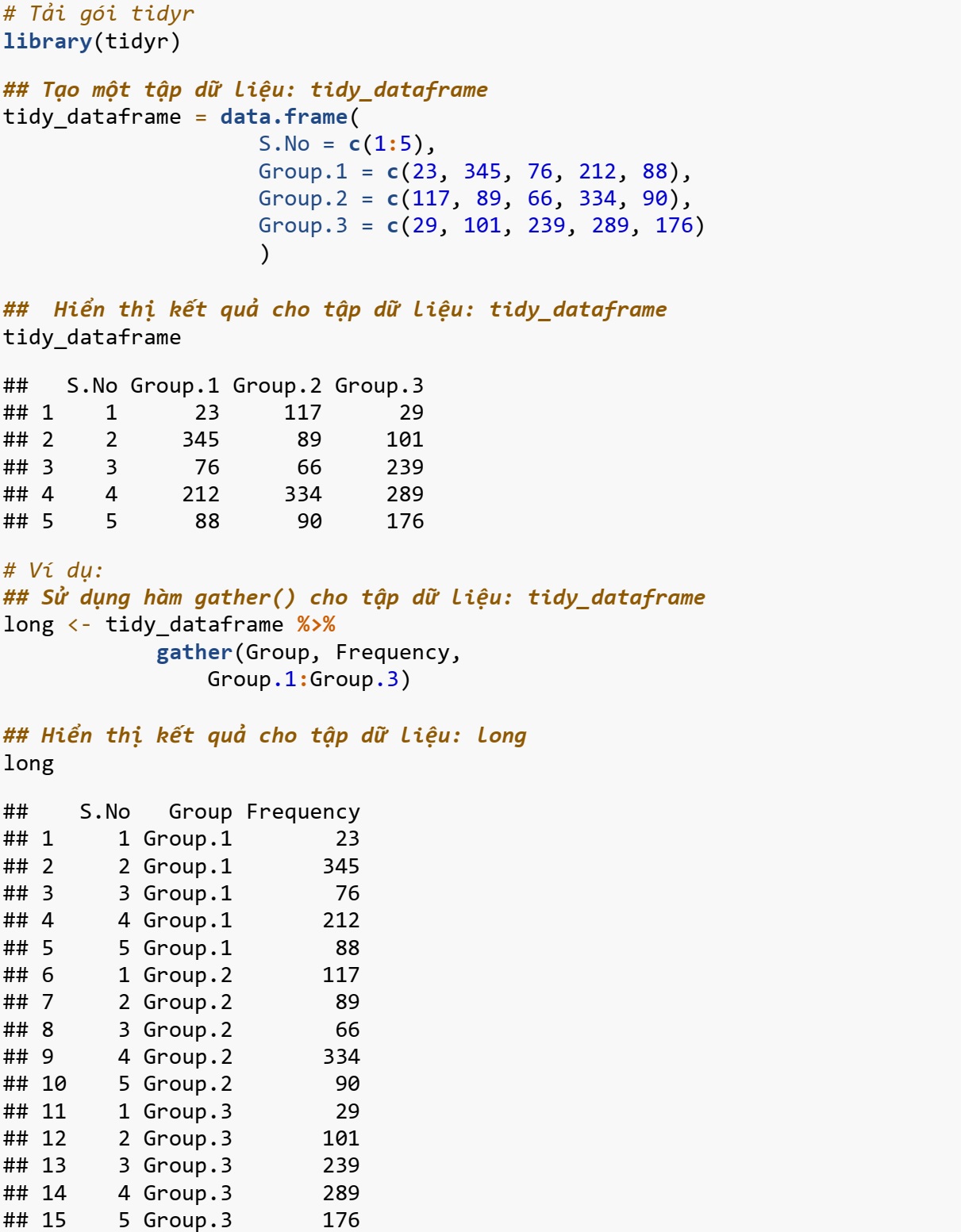
Hàm gather()
Hàm gather() được sử dụng để lấy nhiều cột và gom chúng thành cặp khóa-giá trị.

- data: tập dữ liệu;
- key, value: tên của các cột khóa và giá trị mới dưới dạng chuỗi số hoặc ký tự;
- …: việc lựa chọn các cột. Nếu để trống, tất cả các biến sẽ được chọn;
- na.rm: nếu đặt là TRUE, chương trình sẽ xóa các hàng khỏi đầu ra có cột giá trị là NA;
- convert: nếu đặt là TRUE, chương trình sẽ tự động chạy type.convert() trên cột khóa. Điều này hữu ích nếu các kiểu cột thực sự là số, số nguyên hoặc logic.
- factor_key: nếu FALSE, các giá trị khóa sẽ được lưu trữ dưới dạng vectơ ký tự. Nếu TRUE, các giá trị khóa sẽ được bảo toàn.
Hàm separate()
Hàm separate() được sử dụng để chuyển đổi dữ liệu dài hơn sang định dạng rộng hơn. Hàm separate() chuyển một cột ký tự đơn thành nhiều cột.
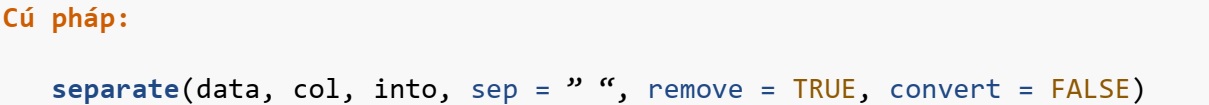
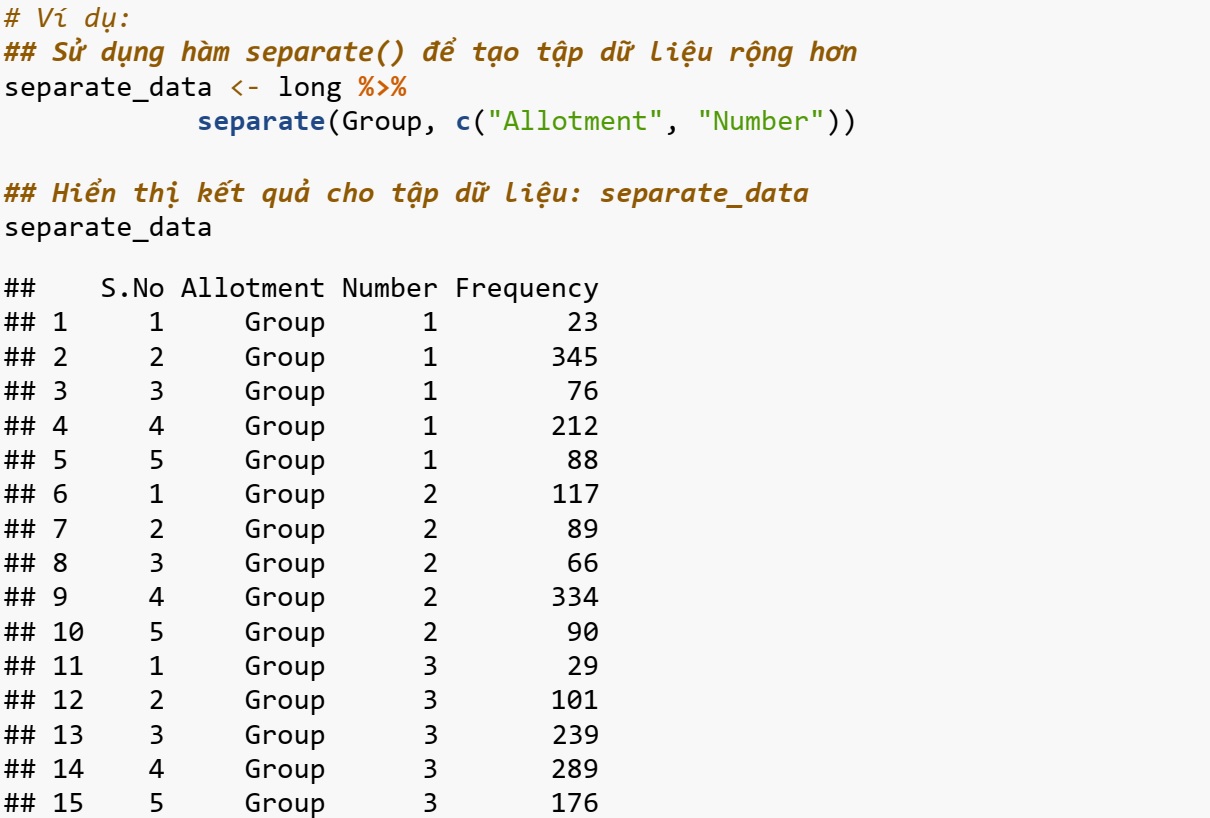
- data: tập dữ liệu;
- col: vị trí của cột;
- into: tên của các biến mới để tạo thành vectơ ký tự. NA được sử dụng để bỏ biến ở đầu ra;
- sep: đấu phân cách giữa các cột;
- remove: nếu đặt là TRUE, chương trình sẽ xóa cột đầu vào khỏi tạp dữ liệu ở đầu ra;
- convert: nếu TRUE, chương trình sẽ chạy type.convert() với as.is = TRUE trên các cột mới.
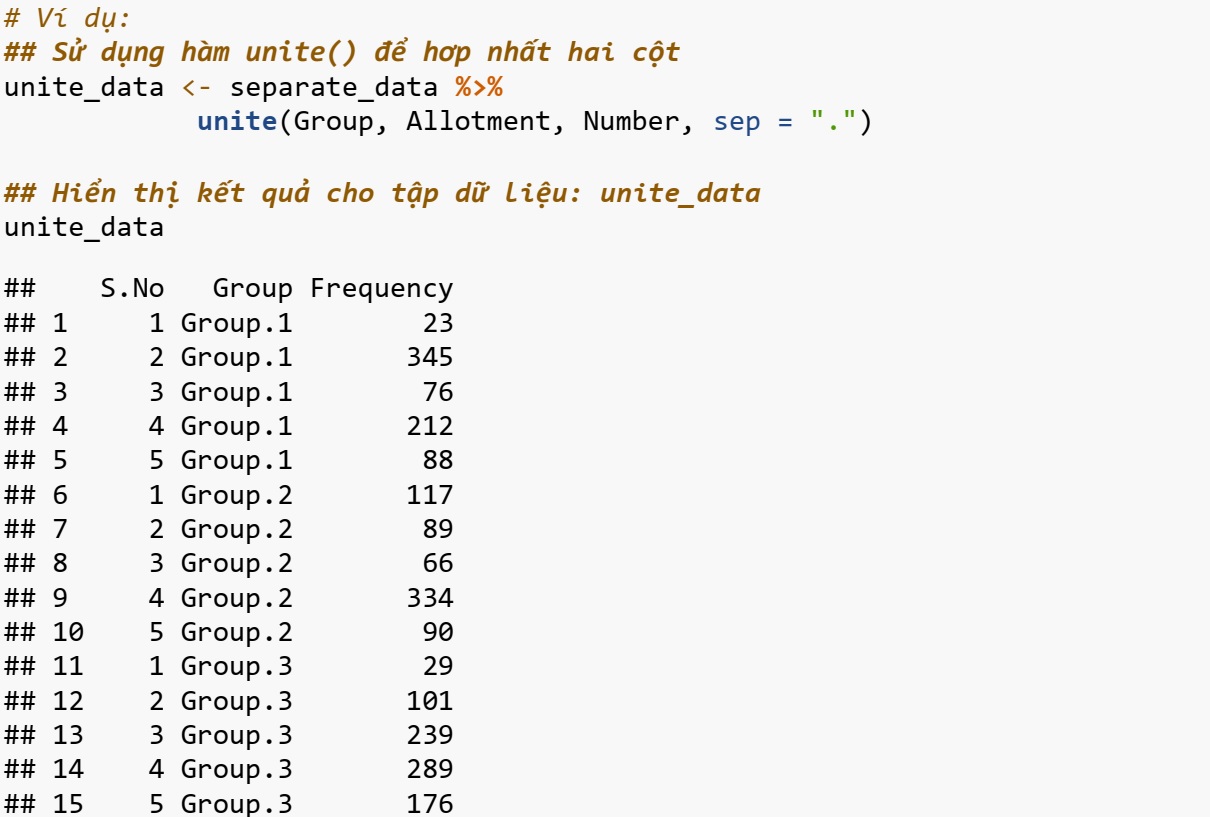
Hàm unite()
Hàm unite() được sử dụng để hợp nhất hai cột thành một cột. Về bản chất, nó kết hợp hai biến của một quan sát duy nhất thành một biến.

- data: tập dữ liệu;
- col: tên của cột mới;
- …: lựa chọn các cột mong muốn; nếu để trống, tất cả các biến sẽ được chọn;
- sep: khoảng cách giữa các giá trị;
- remove: Nếu TRUE, chương trình sẽ xóa các cột đầu vào khỏi tập dữ liệu ở đầu ra.
Hàm spread()
Hàm spread() được sử dụng để chuyển đổi định dạng tập dữ liệu sang dạng rộng hơn.

- data: tập dữ liệu;
- key: tên hoặc vị trí cột;
- value: tên hoặc vị trí cột;
- fill: nếu được gán giá tri thì các giá trị bị khuyết sẽ được thay thế bằng giá trị này;
- convert: nếu TRUE thì type.convert() với asis = TRUE sẽ được chạy trên mỗi cột mới.

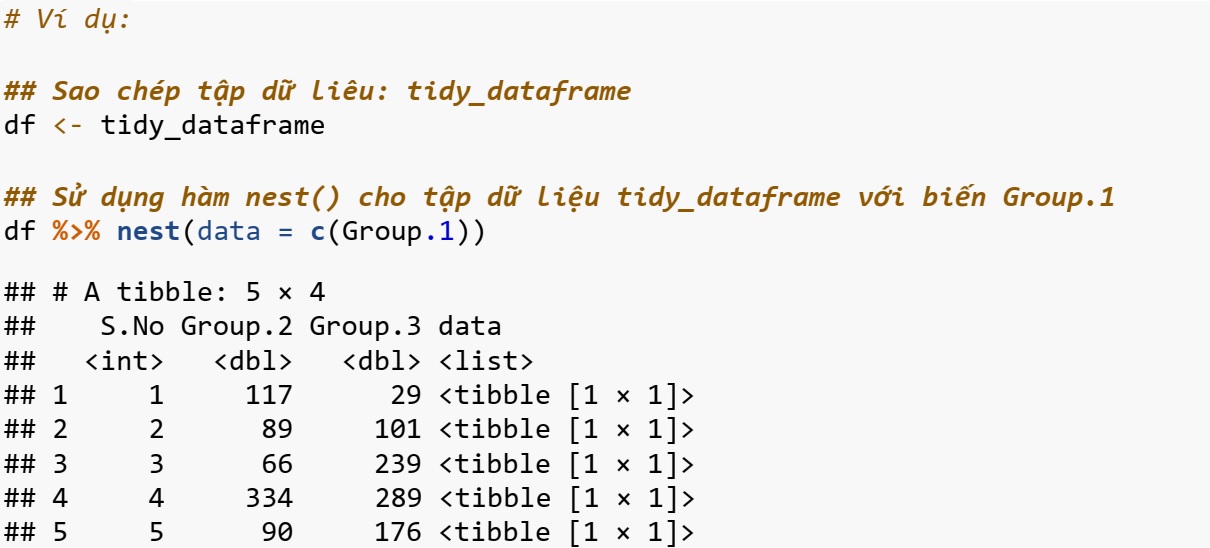
Hàm nest()
Hàm nest() được sử dụng để tạo danh sách các tập dữ liệu chứa tất cả các biến lồng nhau.

- data: tập dữ liệu;
- …: một số cột được chọn; nếu để trống, tất cả các biến sẽ được chọn;
- key: tên của cột mới, dưới dạng chuỗi số hoặc ký tự.
Hàm unnest()
Hàm unnest(): hàm đảo ngược của hàm nest(), hàm biến mỗi phần tử của danh sách thành một hàng riêng.

- data: tập dữ liệu;
- …: chỉ định các cột cần bỏ lồng nhau; nếu bỏ qua, mặc định là tất cả các cột;
- .drop: theo mặc định, nó sẽ bỏ qua nếu chúng ta bỏ lồng nhau các cột được chỉ định;
- .id: định danh của tập dữ liệu;
- .sep: Nếu không phải NULL, tên của các cột trong tập dữ liệu không lồng nhau sẽ kết hợp tên của tên các cột gốc với tên từ tập dữ liệu lồng nhau;
- .preserve: danh sách cột được bảo toàn ở đầu ra.

Hàm fill()
Hàm fill() được sử dụng để điền các giá trị còn thiếu trong các cột đã chọn bằng mục nhập trước đó. Điều này hữu ích trong định dạng đầu ra chung, trong đó các giá trị không được lặp lại, chúng được ghi lại mỗi khi chúng thay đổi. Các giá trị còn thiếu được thay thế trong các vectơ; NULL được thay thế trong danh sách.

- data: tập dữ liệu;
- …: một số cột được chọn; nếu để trống, sẽ không có gì xảy ra;
- direction: Hướng để điền các giá trị còn thiếu; “down” (mặc định) hoặc “up”.

Hàm full_seq()
Hàm full_seq() được sử dụng để điền các giá trị còn thiếu trong một vectơ số.

- x: một véctơ;
- period: khoảng cách giữa mỗi lần quan sát;
- tol: dung sai để kiểm tra tính chu kỳ.
Hàm drop_na()
Hàm drop_na() được sử dụng để xóa các hàng chứa giá trị bị thiếu.

- data: tập dữ liệu;
- …: một số cột được chọn; nếu để trống, tất cả các biến sẽ được chọn.

Hàm replace_na()
Hàm replace_na() được sử dụng để thay thế các giá trị bị thiếu.

- data: tập dữ liệu;
- relace: nếu dữ liệu là một tập dữ liệu, trả về một tập dữ liệu. Nếu dữ liệu là một vectơ, trả về một vectơ.

Nhất Luận
----------------------------------------
Tài liệu tham khảo:
[1] R for Data Science. https://r4ds.had.co.nz/
[2] R for Data Science (2e). https://r4ds.hadley.nz/
[3] R for Data Science. https://bookdown.org/swen/R_for_Data_Science/
[4] R Packages (2e). https://r-pkgs.org/
[5] Advanced R. https://adv-r.hadley.nz/index.html#license
[6] Advanced R Solutions. https://advanced-r-solutions.rbind.io/