Gói dplyr là một cấu trúc thao tác dữ liệu; cung cấp một tập hợp các hàm để thao tác dữ liệu; bao gồm hàm mutate(), transmute(), mutate_all(), mutate_at(), mutate_if(), select(), filter(), summarise(), arrange(), sample_n(), sample_frac(), …
Hàm mutate()
Hàm mutate() được sử dụng để thêm các biến mới vào một data frame (khung dữ liệu); bằng cách thực hiện các thao tác trên các biến hiện có.

- df: một data frame;
- expr: phép toán trên các biến (thuộc tính).

Hàm transmute()
Hàm transmute() được sử dụng để tạo biến mới hoặc sửa đổi biến hiện có trong data frame, đồng thời loại bỏ các biến không phải là một phần của kết quả.

- df: một data frame;
- expr: phép toán trên các biến.

Hàm mutate_if()
Hàm mutate_if() được sử dụng để áp dụng phép biến đổi cho các biến trong một data frame dựa trên một điều kiện cụ thể.
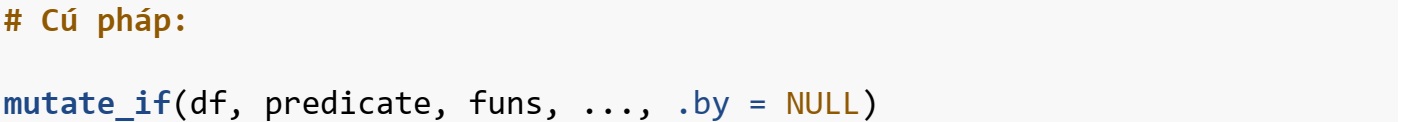
- df: một data frame;
- predicate: hàm lọc;
- funs: hàm cần truyền vào;
- …: các đối số khác truyền vào.

Hàm filter()
Hàm filter() được sử dụng lựa chọn các trường hợp thông qua sử dụng các giá trị của chúng làm cơ sở để thực hiện.

- df: một data frame;
- …: hàm lọc.

Hàm arrange()
Hàm arrange() được sử dụng để sắp xếp thứ tự các bậc của một biến khảo sát.

- df: data frame;
- …: biến hoặc hàm của biến. Sử dụng hàm desc() để sắp xếp biến theo thứ tự giảm dần;
- by_group: sắp xếp theo nhóm biến.

Hàm select()
Hàm select() được sử dụng để trích xuất bảng dữ liệu theo các biến tùy chọn.

- df: một data frame;
- …: cột cần trích xuất hoặc loại bỏ, hoặc hàm trích xuất như startswith(), lọc như contains().

Hàm summarise()
Hàm summarise() được sử dụng để hiển thị một hàm giá trị của một biến khảo sát.

- df: một data frame;
- …: biểu thức của một biến; như min, max, median, ….

Hàm sample_n() và sample_frac()
Hàm sample_n() và sample_frac() được sử dụng để lấy mẫu ngẫu nhiên; hàm sample_n() lấy mẫu ngẫu nhiên theo số lượng, trong khi đó hàm sample_frac() lấy mẫu ngẫu nhiên theo tỉ lệ.

- df: một data frame;
- size: số lượng hay tỉ lệ mẫu cần lấy;
- replace: lấy mẫu có lặp lại hay không, mặc định là lấy mẫu không lặp lại replace=FALSE;
- fac: tên cột nếu $fac được định nghĩa;
- …: các đối số bổ sung.

Cheatsheet


Sơ đồ tóm tắt gói dplyr (Nguồn: https://rstudio.github.io/cheatsheets/data-transformation.pdf)
Nhất Luận
----------------------------------------
Tài liệu tham khảo:
[1] R for Data Science. https://r4ds.had.co.nz/
[2] R for Data Science (2e). https://r4ds.hadley.nz/
[3] R for Data Science. https://bookdown.org/swen/R_for_Data_Science/
[4] R Packages (2e). https://r-pkgs.org/
[5] Advanced R. https://adv-r.hadley.nz/index.html#license
[6] Advanced R Solutions. https://advanced-r-solutions.rbind.io/
[7] dplyr. https://dplyr.tidyverse.org/
[8] tidyverse/dplyr. https://github.com/tidyverse/dplyr