R là ngôn ngữ lập trình mã nguồn mở được sử dụng cho phần mềm thống kê và công cụ phân tích dữ liệu. Đây là công cụ quan trọng cho Khoa học dữ liệu. R rất phổ biến và là lựa chọn hàng đầu của nhiều nhà thống kê và nhà khoa học dữ liệu. R có các công cụ mạnh mẽ để tạo ra hình ảnh trực quan, mang tính thẩm mỹ cao, hỗ trợ trích xuất, chuyển đổi và tải dữ liệu. Với giao diện cho SQL, bảng tính,… R cung cấp các gói thiết yếu để dọn dẹp và chuyển đổi dữ liệu, cho phép áp dụng thuật toán máy học để dự đoán các sự kiện trong tương lai và hỗ trợ phân tích dữ liệu phi cấu trúc thông qua giao diện cơ sở dữ liệu NoSQL.
Cú pháp và Biến trong R
Trong R, sử dụng toán tử <- để gán giá trị cho các biến, cho dù toán tử = cũng thường được sử dụng. Cũng có thể thêm chú thích vào mã để giải thích những gì đang xảy ra, bằng cách sử dụng ký hiệu #

Kiểu dữ liệu và cấu trúc trong R
Trong R, dữ liệu được lưu trữ trong nhiều cấu trúc khác nhau, chẳng hạn như vectơ, ma trận, danh sách và khung dữ liệu.
Vectơ
Vectơ như các mảng đơn giản chứa nhiều giá trị cùng loại; có thể tạo một vectơ bằng hàm c().

Ma trận
Ma trận là mảng hai chiều trong đó mỗi phần tử có cùng kiểu dữ liệu. Tạo ma trận bằng hàm matrix().

Danh sách
Danh sách có thể chứa các phần tử có nhiều kiểu khác nhau, bao gồm số, chuỗi, vectơ và một danh sách khác bên trong. Danh sách được tạo bằng hàm list().

Khung dữ liệu
Khung dữ liệu là cấu trúc dữ liệu được sử dụng phổ biến nhất trong R. Chúng giống như bảng, trong đó mỗi cột có thể chứa các kiểu dữ liệu khác nhau. Sử dụng hàm data.frame() để tạo một khung dữ liệu.

Trong R, một số thư viện được yêu cầu cho các tác vụ như thao tác dữ liệu và mô hình thống kê để trực quan hóa và học máy. Các thư viện chính bao gồm: dplyr, tidyr, ggplot2, xgboost, shiny, data.table.
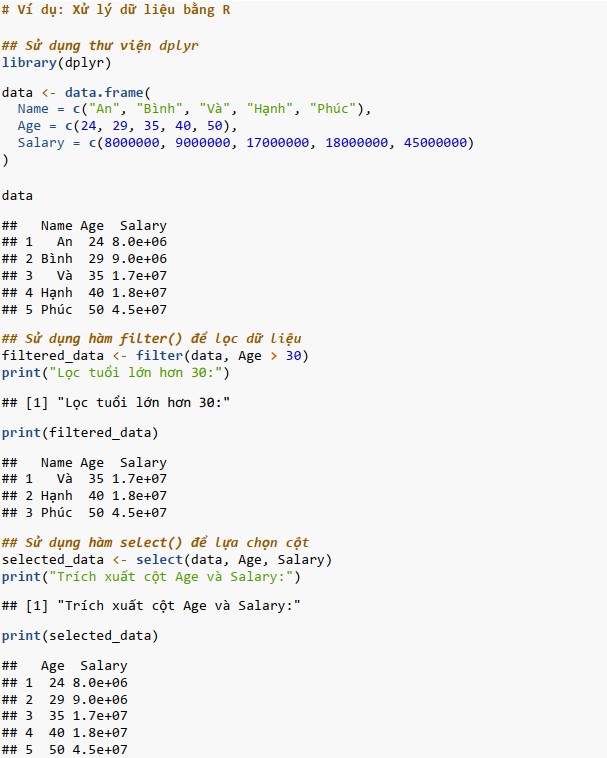
Xử lý dữ liệu bằng R
Thư viện R cung cấp các gói xử lý dữ liệu, cho phép phân tích dọn dẹp, chuyển đổi và tóm tắt các tập dữ liệu một cách hiệu quả. Sử dụng gói dplyr để xử lý dữ liệu. Gói này cung cấp một tập hợp các chức năng giúp dễ dàng thao tác các khung dữ liệu. Một số chức năng chính bao gồm: hàm filter(): lọc các hàng dựa trên điều kiện, hàm select(): chọn các cột cụ thể, hàm mutate(): thêm hoặc sửa đổi các cột, hàm arrange(): sắp xếp các hàng theo các cột được chỉ định, sumsum(): tóm tắt dữ liệu bằng cách áp dụng các hàm.
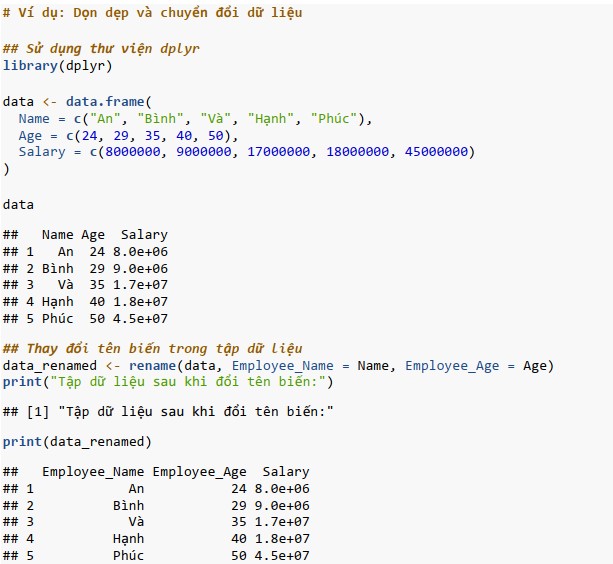
Dọn dẹp và chuyển đổi dữ liệu
Làm sạch dữ liệu bao gồm việc sửa hoặc xóa lỗi và chuyển đổi dữ liệu sang định dạng có thể sử dụng được. Các chuyển đổi chính bao gồm: rename(): để đổi tên các cột, as.character(): để thay đổi kiểu dữ liệu, mutate(): để tạo ra các biến dẫn xuất.
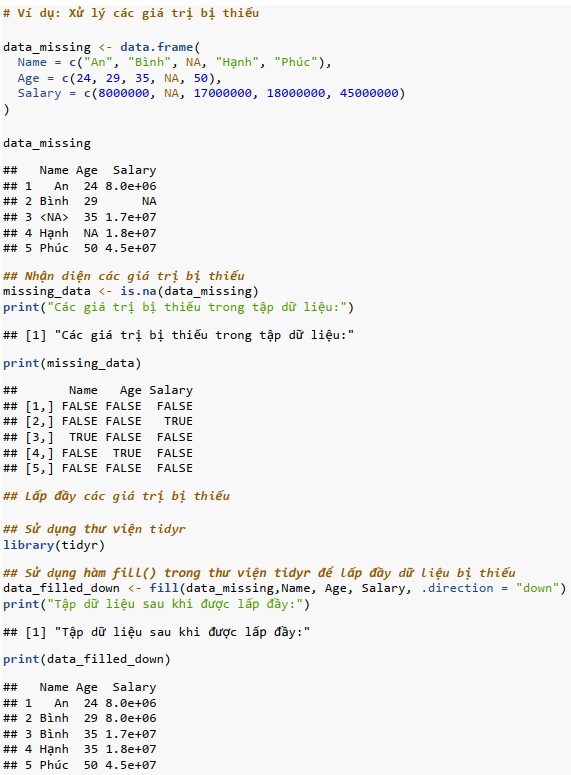
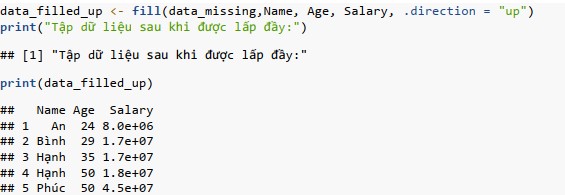
Xử lý các giá trị bị thiếu
Xử lý các giá trị bị thiếu là một phần thiết yếu của quá trình chuẩn bị dữ liệu. R cung cấp một số hàm để xác định, xử lý và thay thế các giá trị bị thiếu trong tập dữ liệu. Các hàm chính bao gồm: hàm is.na(): để xác định các giá trị bị thiếu trong dữ liệu, hàm na.omit(): để xóa các hàng có giá trị bị thiếu, ifelse(): để thay thế các giá trị bị thiếu bằng một giá trị cụ thể hoặc kết quả tính toán, hàm tidyr::fill(): để điền các giá trị bị thiếu bằng cách sử dụng giá trị không bị thiếu trước đó hoặc tiếp theo trong cột.
Phân tích thống kê trong R
R cung cấp các công cụ để thực hiện cả phân tích thống kê mô tả và suy luận, vì vậy nó trở thành lựa chọn ưu tiên của các nhà thống kê và nhà khoa học dữ liệu.
Thống kê mô tả
Thống kê mô tả cung cấp tóm tắt các đặc điểm chính của dữ liệu bằng các biện pháp như trung bình, trung vị, phương sai và độ lệch chuẩn. Các hàm này bao gồm: mean(): tính giá trị trung bình của một tập dữ liệu, median(): xác định giá trị ở giữa trong một tập dữ liệu, sd(): tính độ lệch chuẩn, summary(): cung cấp bản tóm tắt các số liệu thống kê mô tả quan trọng.

Thống kê suy luận
Thống kê suy luận cho phép bạn đưa ra dự đoán hoặc khái quát về một quần thể dựa trên dữ liệu mẫu. Bao gồm kiểm định giả thuyết và phân tích tương quan và hồi quy.
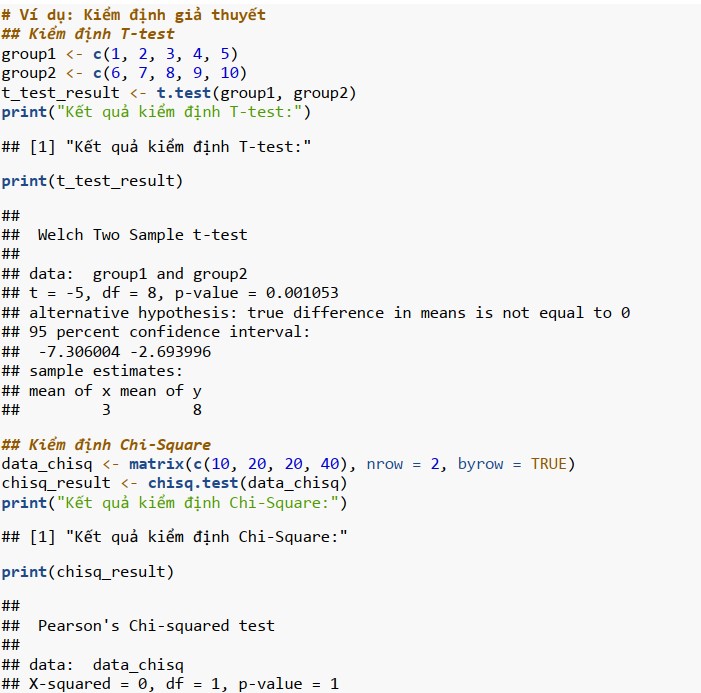
Kiểm định giả thuyết:
• t.test(): Thực hiện kiểm định t để so sánh giá trị trung bình giữa hai nhóm.
• aov(): Thực hiện Phân tích phương sai (ANOVA) để so sánh các giá trị trung bình giữa ba hoặc nhiều nhóm.
• chisq.test(): Thực hiện các thử nghiệm Chi-Square để xác định tính độc lập hoặc mức độ phù hợp.
• wilcox.test(): Một bài kiểm tra phi tham số so sánh hai mẫu độc lập (bài kiểm tra tổng hạng Wilcoxon).
• ks.test(): Kiểm định Kolmogorov-Smirnov so sánh hai phân phối để xem chúng có giống nhau không.
• fisher.test(): Kiểm định chính xác của Fisher được sử dụng cho kích thước mẫu nhỏ trong các bảng dự phòng.
Phân tích tương quan và hồi quy
Các kỹ thuật này khám phá mối quan hệ giữa các biến:
• Phân tích tương quan: Đo lường cường độ và hướng của mối quan hệ bằng cách sử dụng hàm cor().
• Phân tích hồi quy: Mô hình hóa mối quan hệ tuyến tính bằng hàm lm().

Học máy với R
Học máy trong R cho phép các nhà phân tích xây dựng các mô hình dự đoán, thực hiện phân loại và khám phá các mẫu trong dữ liệu.
Học có giám sát
Hồi quy tuyến tính được sử dụng để dự đoán kết quả số liên tục dựa trên một hoặc nhiều yếu tố dự báo. Trong R, chúng ta có thể dự đoán kết quả số liên tục bằng cách sử dụng hàm lm().

Hồi quy logistic được sử dụng cho các tác vụ phân loại nhị phân trong đó biến kết quả là biến phân loại (ví dụ: 0 hoặc 1), trong R, hồi quy logistic được thực hiện bằng hàm glm().

Cây quyết định
Cây quyết định được sử dụng cho cả nhiệm vụ phân loại và hồi quy.

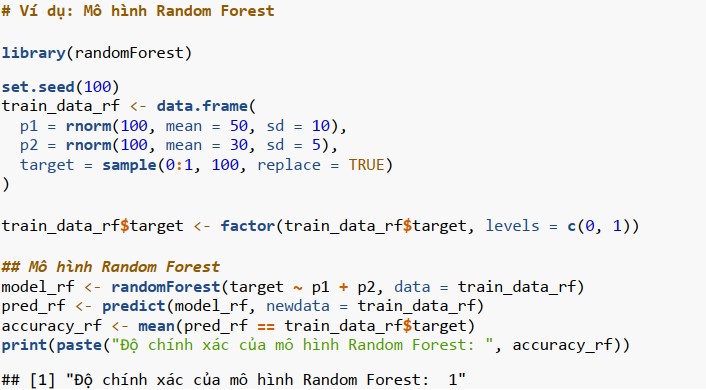
Random Forest
Random Forest là một kỹ thuật học tập tổng hợp để thực hiện phân loại và hồi quy bằng cách sử dụng hàm randomForest().
Học không giám sát
Học không giám sát liên quan đến việc học các mẫu dữ liệu không có đầu ra được gắn nhãn. Các kỹ thuật phổ biến bao gồm phân cụm và giảm chiều.
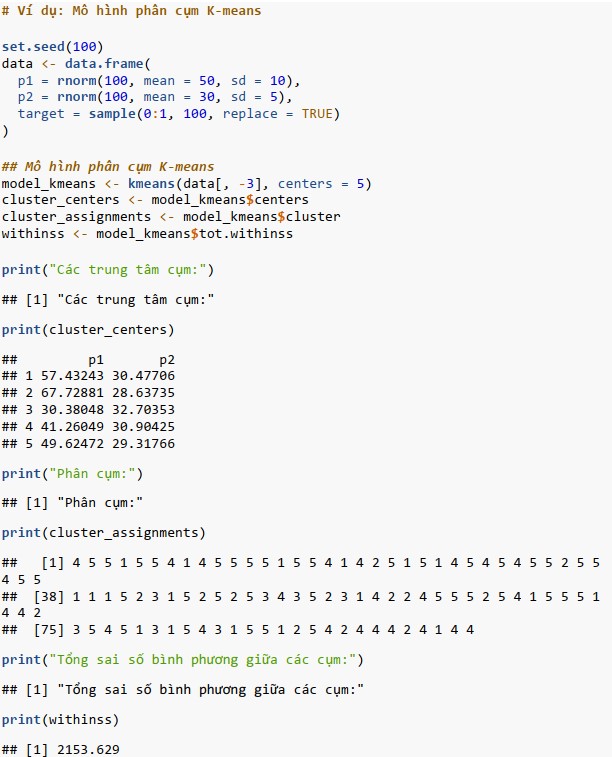
Phân cụm K-means
Phân cụm K-means phân chia dữ liệu thành K cụm dựa trên khoảng cách giữa các điểm dữ liệu. Trong R, hàm kmeans() được sử dụng để thực hiện phân cụm.
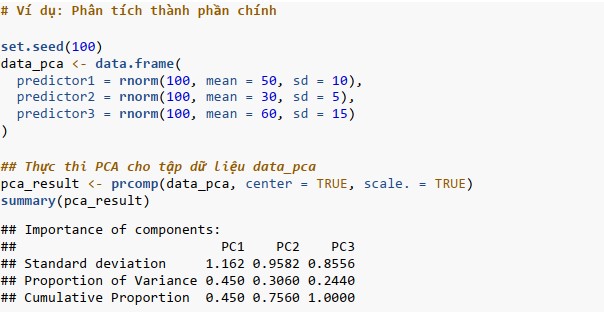
Phân tích thành phần chính (PCA)
PCA chuyển đổi dữ liệu thành một hệ tọa độ mới trong đó các trục biểu diễn hướng của phương sai lớn nhất. Trong R, PCA được thực hiện bằng hàm prcomp().
Nhất Luận
----------------------------------------
Tài liệu tham khảo:
[1] R for Data Science. https://r4ds.had.co.nz/
[2] R for Data Science (2e). https://r4ds.hadley.nz/
[3] R for Data Science. https://bookdown.org/swen/R_for_Data_Science/
[4] R Packages (2e). https://r-pkgs.org/
[5] Advanced R. https://adv-r.hadley.nz/index.html#license
[6] Advanced R Solutions. https://advanced-r-solutions.rbind.io/