Học máy (Mahine Learning) là một lĩnh vực nghiên cứu cho phép máy tính tự học hỏi mà không cần lập trình cụ thể. Quá trình này được thực hiện bằng cách cung cấp dữ liệu, sau đó huấn luyện máy tính bằng cách xây dựng các mô hình học máy sử dụng dữ liệu và các thuật toán liên quan. Việc lựa chọn thuật toán phụ thuộc vào loại dữ liệu và nhiệm vụ mà chúng ta đang cố gắng tự động hóa. Nhìn chung, có bốn loại hình học máy chính sau đây:
- Học có giám sát (Supervised Learning): Trong học có giám sát, mô hình được huấn luyện trên một tập dữ liệu đã được gán nhãn, nghĩa là mỗi điểm dữ liệu đều có một đầu ra tương ứng. Mục tiêu là để mô hình học cách ánh xạ dữ liệu đầu vào tới đầu ra chính xác. Ví dụ như phân loại email là spam hay không spam, hoặc dự đoán giá nhà dựa trên các thuộc tính cho trước.
- Học không giám sát (Unsupervised Learning): Ngược lại với học có giám sát, học không giám sát được thực hiện với các tập dữ liệu không có gán nhãn. Mục tiêu là tìm kiếm các cấu trúc, mẫu hoặc mối quan hệ tiềm ẩn trong dữ liệu. Ví dụ như phân nhóm khách hàng dựa trên hành vi mua sắm, hoặc giảm chiều dữ liệu để dễ dàng phân tích hơn.
- Học bán giám sát (Semi-supervised Learning): Đây là sự kết hợp giữa học có giám sát và học không giám sát. Mô hình được huấn luyện trên một lượng lớn dữ liệu không có nhãn và một lượng nhỏ dữ liệu có nhãn. Học bán giám sát đặc biệt hữu ích khi việc gán nhãn dữ liệu là tốn kém hoặc khó khăn.
- Học tăng cường (Reinforcement Learning): Trong học tăng cường, một tác nhân học cách đưa ra quyết định bằng cách tương tác với môi trường. Tác nhân nhận được phần thưởng hoặc hình phạt dựa trên hành động của mình, và mục tiêu là tối đa hóa tổng số phần thưởng theo thời gian. Ví dụ như huấn luyện robot đánh cờ, chơi trò chơi, đi lại, ….
Học có giám sát
Học có giám sát là việc học mà trong đó chúng ta dạy đào tạo máy bằng dữ liệu được gắn nhãn tốt, nghĩa là đa số dữ liệu đã được gắn nhãn với câu trả lời đúng. Sau đó, máy được cung cấp một tập hợp các dữ liệu mới để thuật toán học có giám sát phân tích dữ liệu đào tạo và tạo ra kết quả đúng từ dữ liệu được gắn nhãn. Học có giám sát được phân loại thành hai loại sau đây:
- Phân loại (Classification): việc phân loại xảy ra khi biến đầu ra là một danh mục, chẳng hạn như “chó và mèo”, hoặc “xanh và đỏ”, hoặc “bệnh và không bệnh”,… Phân loại bao gồm cây quyết định (Decision Trees), phân loại Bayes (Naive Bayes Classifiers), phân loại KNN (K-NN Classifiers) và SVM’s (Support Vector Machines).
- Hồi quy (Regression): vấn đề hồi quy xảy ra khi biến đầu ra là giá trị thực, chẳng hạn như giá nhà, cân nặng, phần trăm,… Hồi quy gồm: hồi quy đơn biến, hồi quy đa biến và Hồi quy logistic.

Ở đây, Y là hàm mục tiêu có chứa biến phụ thuộc cần dự đoán và model là công thức cho mô hình học có giám sát đã chọn. Đặc biệt, ký hiệu lm() được quy ước cho việc sử dụng mô hình hồi quy đơn biến.
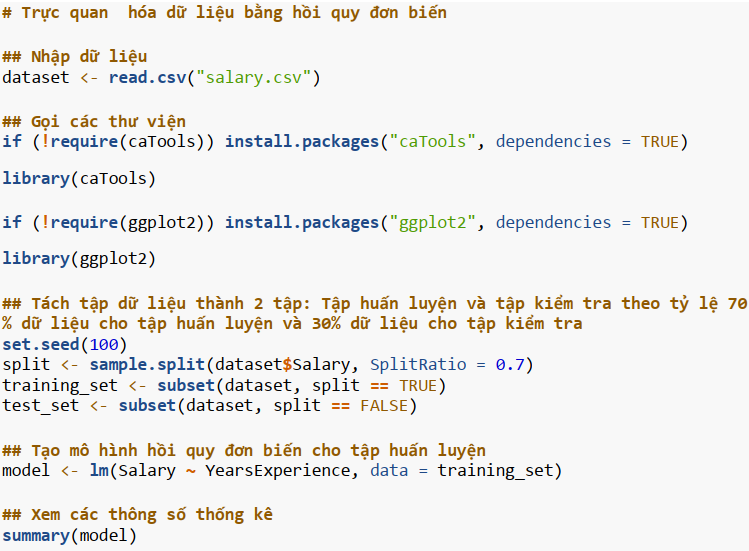
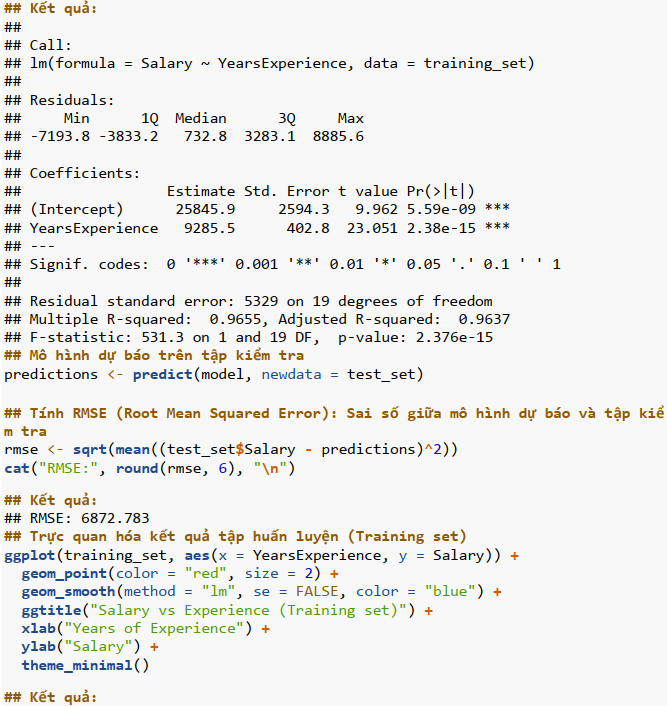
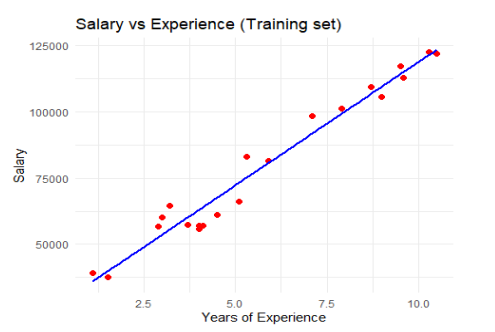
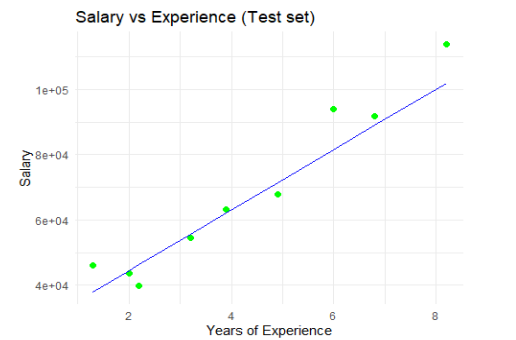
Ví dụ học có giám sát bằng mô hình hồi quy đơn biến
Xét tập dữ liệu Salary_data.csv; ở đây Y là mức lương và biến phụ thuộc là số năm làm việc.

Học không giám sát
Học không giám sát là quá trình đào tạo máy sử dụng thông tin không được phân loại hoặc dán nhãn và cho phép thuật toán quyết định trên thông tin đó mà không cần chỉ dẫn. Ở đây, nhiệm vụ là nhóm thông tin chưa được sắp xếp theo điểm giống nhau, mẫu và khác biệt mà không cần bất kỳ quá trình đào tạo dữ liệu nào trước đó. Học không giám sát được chia thành hai loại:
- Phân cụm (Clustering): phân cụm để khám phá các nhóm vốn có trong dữ liệu, chẳng hạn như nhóm khách hàng theo hành vi mua hàng. Phân cụm bao gồm: Hierarchical clustering, K-means clustering, K-NN (k nearest neighbors), PCA (Principal Component Analysis), Singular Value Decomposition, Independent Component Analysis.
- Liên kết (Association): học quy tắc liên kết là vấn đề mà bạn muốn khám phá các quy tắc mô tả phần lớn dữ liệu của mình, chẳng hạn như những người mua A cũng có xu hướng mua B.
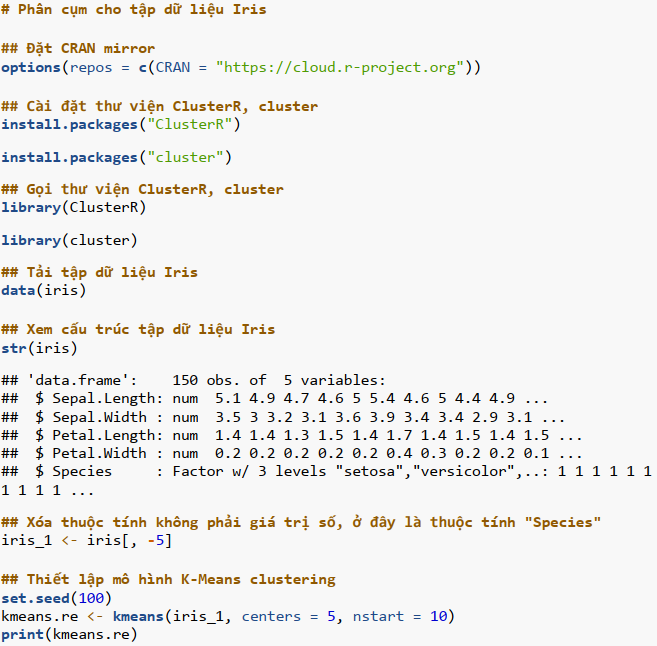
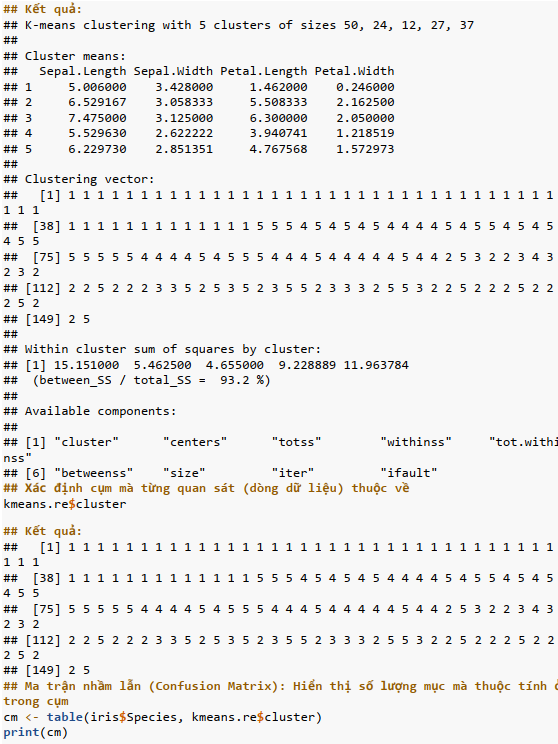
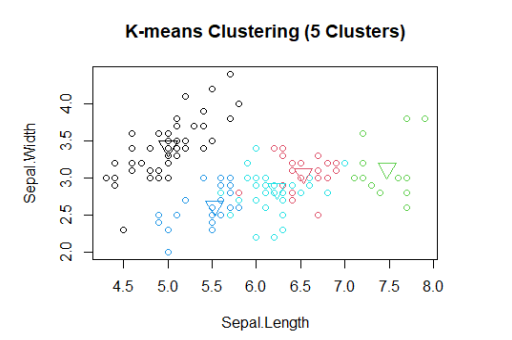
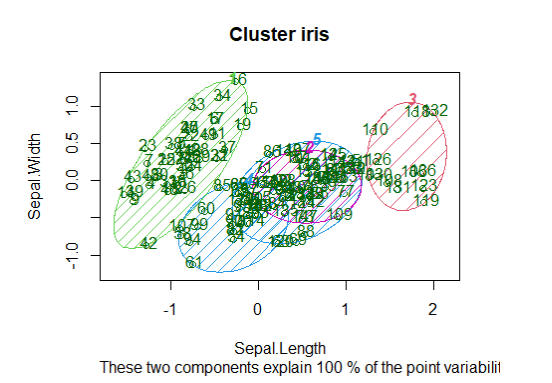
Ví dụ học không giám sát bằng mô hình K-means clustering
Phân cụm K-means (K-means clustering) trong R là mô hình phi tuyến tính không giám sát, cụm dữ liệu dựa trên sự giống nhau hoặc các nhóm tương tự. Mô hình phân chia các quan sát thành một số cụm được chỉ định trước. Phân đoạn dữ liệu diễn ra để gán từng ví dụ đào tạo cho một phân đoạn được gọi là cụm.

Ở đây:
- x: dữ liệu số;
- centers: số lượng cụm được xác định trước;
- nstart: số thành phần ngẫu nhiên được lặp lại.



Kết luận
Trong R, học có giám sát và học không giám sát đều là những công cụ mạnh mẽ để giải quyết các vấn đề phân tích dữ liệu phức tạp. Học có giám sát lý tưởng cho các nhiệm vụ dự đoán khi có sẵn dữ liệu gán nhãn, cho phép xây dựng các mô hình có khả năng khái quát hóa cao. Ngược lại, học không giám sát là lựa chọn tốt để khám phá các mẫu tiềm ẩn, giảm độ phức tạp của dữ liệu, và hiểu sâu hơn về cấu trúc dữ liệu khi không có nhãn. Việc lựa chọn phương pháp phù hợp phụ thuộc vào đặc tính của dữ liệu, mục tiêu phân tích, và mức độ có sẵn của nhãn dữ liệu.
Nhất Luận
----------------------------------------
Tài liệu tham khảo:
[1] R for Data Science. https://r4ds.had.co.nz/
[2] R for Data Science (2e). https://r4ds.hadley.nz/
[3] R for Data Science. https://bookdown.org/swen/R_for_Data_Science/
[4] R Packages (2e). https://r-pkgs.org/
[5] Advanced R. https://adv-r.hadley.nz/index.html#license
[6] Advanced R Solutions. https://advanced-r-solutions.rbind.io/
[7] Machine Learning with R. https://tuanvanle.wordpress.com/2017/04/19/machine-learning-with-r/
[8] Giới thiệu về Machine Learning. https://machinelearningcoban.com/2016/12/26/introduce/
[9] Salary_data.csv. https://www.kaggle.com/datasets/ravitejakotharu/salary-datacsv