Học có giám sát (Supervised Learning) là mô hình dữ liệu được huấn luyện trên một tập dữ liệu đã được gán nhãn; tùy vào đặc tính của tập dữ liệu mà có thể sử dụng các mô hình phân loại và hồi quy khác nhau: mô hình Cây quyết định (Decision Trees), mô hình Random Forest, mô hình Bayes (Naive Bayes Classifiers), mô hình KNN (K-NN Classifiers) và mô hình SVM (Support Vector Machines), hồi quy đơn biến, hồi quy đa biến, hồi quy logistic.
Học có giám sát bằng mô hình Random Forest
Mô hình Random Forest được sử dụng cho cả phân loại (classification) và hồi quy (regression). Random Forest tạo ra một lượng lớn các cây quyết định độc lập và sau đó kết hợp các dự đoán của chúng; thay vì chỉ dựa vào một cây quyết định duy nhất (có thể dẫn đến overfitting), Random Forest sử dụng đa dạng nhiều cây để đưa ra quyết định cuối cùng. Mỗi cây được xây dựng từ một tập hợp con ngẫu nhiên của dữ liệu huấn luyện và một tập hợp con ngẫu nhiên của các đặc trưng. Mô hình được sử dụng để phân loại email, dự báo tài chính, chứng khoán, hành vi khách hàng, phát hiện gian lận tài chính, chuẩn đoán bệnh trong y tế, nhận diện hình ảnh, phân loại văn bản, nhận dạng hình ảnh, phân đoạn khách hàng,…
Ví dụ học có giám sát bằng mô hình Random Forest trong R
Để xây dựng một mô hình Random Forest trong R, chúng ta thực hiện các bước tuần tự sau đây:
- Chuẩn bị dữ liệu;
- Xây dựng mô hình Random Forest;
- Đánh giá mô hình;
- Trực quan hóa kết quả mô hình;
- Diễn giải kết quả.


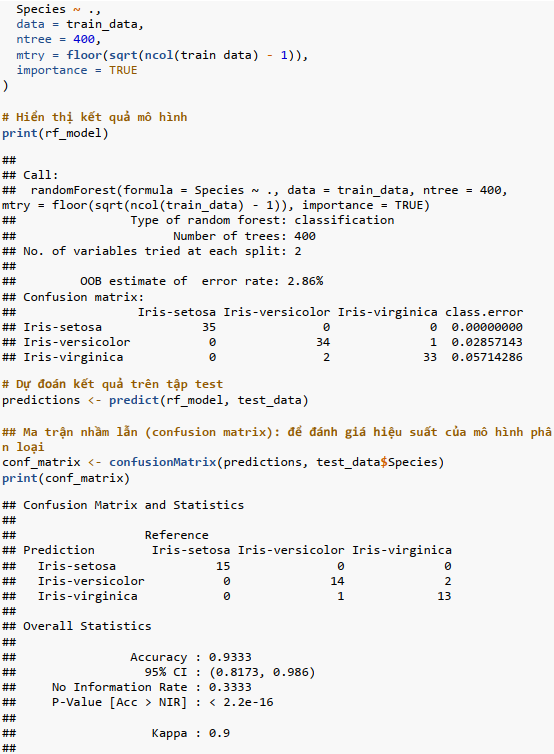
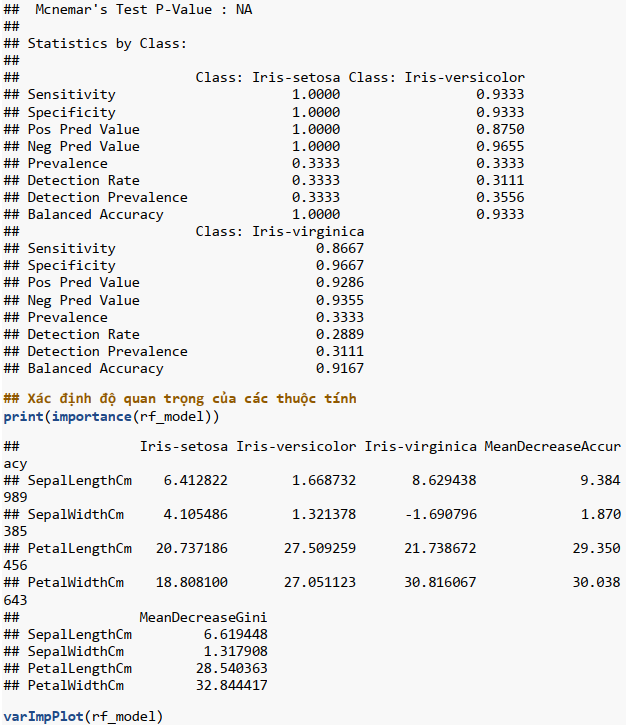
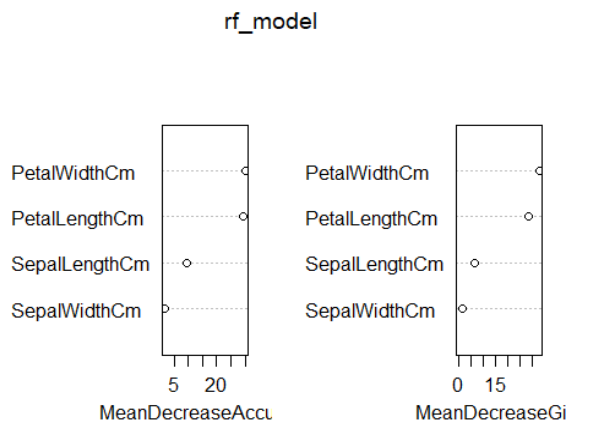

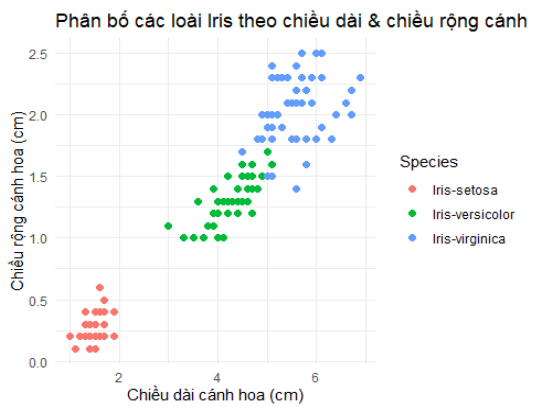
Diễn giải kết quả: Mô hình random forest trên tập test có độ chính xác (accuracy) 93.33%.
Học có giám sát bằng mô hình SVM
Mô hình SVM được sử dụng chủ yếu cho các bài toán phân loại nhị phân. Mục tiêu chính của mô hình là đi tìm một siêu phẳng (hyperplane) tốt nhất để phân tách dữ liệu thành các lớp khác nhau, sao cho khoảng cách từ siêu phẳng đến các điểm dữ liệu gần nhất ở mỗi lớp là lớn nhất. Dạng hình học của siêu phẳng tùy thuộc vào đặc tính của tập dữ liệu xem xét; nếu siêu phẳng là một đường thẳng hoặc mặt phẳng thì mô hình SVM được gọi là mô hình SVM tuyến tính; ngược lại thì được gọi là mô hình SVM phi tuyến. Mô hình SVM thường được ứng dụng trong phân loại văn bản và xử lý ngôn ngữ tự nhiên, nhận dạng hình ảnh và thị giác máy tính, phân loại gene trong nghiên cứu di truyền, chẩn đoán bệnh qua dữ liệu MRI/X-quang, hệ thống gợi ý, dự báo thị trường, xử lý tín hiệu âm thanh.
Ví dụ học có giám sát bằng mô hình SVM trong R
Để xây dựng một mô hình SVM trong R, chúng ta thực hiện các bước tuần tự sau đây:
- Chuẩn bị dữ liệu;
- Xây dựng mô hình SVM;
- Đánh giá mô hình;
- Trực quan hóa kết quả mô hình;
- Diễn giải kết quả.

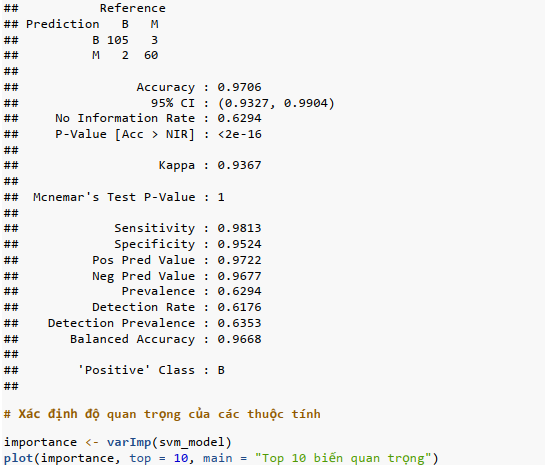
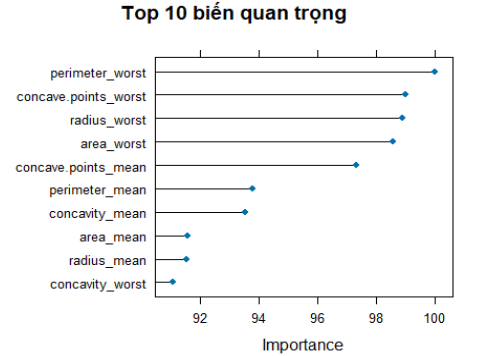
Diễn giải kết quả: Mô hình SVM trên tập test có độ chính xác (accuracy) 97.06%.
Kết Luận
Hai mô hình Random Forest và SVM đều là những công cụ mạnh trong học máy, nhưng chúng có những điểm mạnh và yếu khác nhau:
Mô hình Random Forest thường phù hợp với các mô hình mạnh, ổn định và không cần giải thích chi tiết và không phù hợp tập dữ liệu rất lớn hoặc có quá nhiều cây.
Mô hình SVM thường phù hợp với dữ liệu có số chiều cao, cần biên phân lớp rõ ràng và có thể sử dụng kernel để xử lý phi tuyến và không phù hợp khi tập dữ liệu bị nhiễu hoặc số lượng mẫu rất lớn.
Nhất Luận
----------------------------------------
Tài liệu tham khảo:
[1] R for Data Science. https://r4ds.had.co.nz/
[2] R for Data Science (2e). https://r4ds.hadley.nz/
[3] R for Data Science. https://bookdown.org/swen/R_for_Data_Science/
[4] R Packages (2e). https://r-pkgs.org/
[5] Advanced R. https://adv-r.hadley.nz/index.html#license
[6] Advanced R Solutions. https://advanced-r-solutions.rbind.io/
[7] Machine Learning with R. https://tuanvanle.wordpress.com/2017/04/19/machine-learning-with-r/
[8] Iris Species. https://www.kaggle.com/datasets/uciml/iris?select=Iris.csv
[9] Breast Cancer Wisconsin (Diagnostic) Data Set. https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data?select=data.csv