Học có giám sát (Supervised Learning) là mô hình dữ liệu được huấn luyện trên một tập dữ liệu đã được gán nhãn; tùy vào đặc tính của tập dữ liệu mà chúng ta có thể sử dụng các mô hình phân loại và hồi quy khác nhau: Mô hình Cây quyết định (Decision Trees), mô hình Random Forest, Mô hình Bayes (Naive Bayes Classifiers), Mô hình KNN (K-NN Classifiers) và mô hình SVM (Support Vector Machines), hồi quy đơn biến, hồi quy đa biến, hồi quy logistic.
Học có giám sát bằng mô hình Naive Bayes
Mô hình Naive Bayes dựa trên Định lý xác suất Bayes với giả định tiên nghiệm rằng tất các các thuộc tính (features) đều độc lập với nhau khi đã biết các lớp nhãn.
Công thức của Định lý xác suất Bayes như sau:
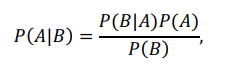
ở đây:
- P(A|B): xác suất của sự kiện A xảy ra khi biết sự kiện B đã xảy ra; được gọi là xác suất hậu nghiệm;
- P(B|A): xác suất của sự kiện B xảy ra khi biết sự kiện A đã xảy ra; được gọi là xác suất khả năng;
- P(A): xác suất của sự kiện A xảy ra; được gọi là xác suất tiên nghiệm của sự kiện A;
- P(B): xác suất của sự kiện B xảy ra; được gọi là xác suất tiên nghiệm của sự kiện B.
Mô hình Naive Bayes được sử dụng để phân loại các điểm dữ liệu vào các lớp khác nhau bằng cách tính toán xác suất một điểm dữ liệu thuộc về một lớp nhất định dựa trên giả định tiên nghiệm là các thuộc tính của điểm dữ liệu là độc lập với nhau. Cụ thể, giả sử chúng ta có một tập dữ liệu với các n thuộc tính X1,X2,...,Xn với k lớp C1,...,Ck. Mục tiêu của mô hình Naive Bayes là tìm ra một lớp mà ở đó mà điểm dữ liệu x=(x1,...,xn ) có xác suất cao nhất để thuộc về.
Nguyên lý hoạt động của mô hình Naive Bayes
Giả sử có một tập các lớp C={C1,C2,…,Ck} và một vector thuộc tính x=(x1,x2,…,xn) là một điểm dữ liệu. Mục tiêu của mô hình là tính toán:
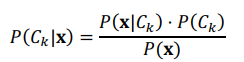
Với giả định độc lập giữa các thuộc tính:
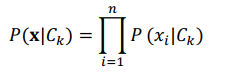
Áp dụng công thức xác xuất Bayes; thu được mô hình sau:
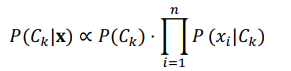
Khi đó, mô hình sẽ tính xác suất hậu nghiệm cho tất cả các lớp và chọn lớp có xác suất cao nhất làm nhãn dự đoán cho mẫu dữ liệu mới
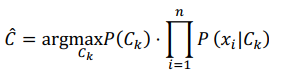
Ứng dụng của mô hình Naive Bayes
Mô hình Naive Bayes đã được ứng dụng trong:
- Phân loại email: phân loại email dựa trên tần suất từ khóa.
- Chẩn đoán y tế: dự đoán bệnh dựa trên triệu chứng.
- Phân tích cảm xúc: đánh giá thái độ tích cực/tiêu cực trong bình luận.Hệ thống đề xuất: Gợi ý sản phẩm dựa trên lịch sử mua hàng.
Ưu và nhược điểm của mô hình Naive Bayes
Ưu điểm
- Đơn giản và dễ triển khai: mô hình dễ hiểu, dễ cài đặt và yêu cầu tính toán tham số không phức tạp.
- Tốc độ xử lý nhanh: phù hợp với các tập dữ liệu lớn hoặc yêu cầu dự đoán thời gian thực.
- Hiệu quả với dữ liệu nhiều chiều: đặc biệt tốt trong các bài toán phân loại văn bản với số lượng thuộc tính lớn.
- Hoạt động tốt ngay cả khi dữ liệu huấn luyện bị giới hạn.
- Xử lý tốt các thuộc tính dạng phân loại và số, giả định dữ liệu theo phân phối chuẩn.
Nhược điểm
- Giả định độc lập không thực tế: trong thực tế, các thuộc tính thường có mối liên hệ với nhau, nên giả định này có thể làm giảm độ chính xác mô hình.
- Vấn đề tần suất bằng 0 (Zero Frequency): nếu một thuộc tính chưa từng xuất hiện trong dữ liệu huấn luyện nhưng lại xuất hiện trong dữ liệu mới thì xác suất sẽ bằng 0; điều này làm sai lệch kết quả.
- Phụ thuộc vào phân phối tiền nghiệm: nếu phân phối tiên nghiệm không chính xác sẽ dẫn đến hiệu suất mô hình giảm.
Các Biến Thể Chính của Mô hình Naive Bayes
Mô hình Native Bayes có ba biến thể chính: Gaussian Naive Bayes, Multinomial Naive Bayes và Bernoulli Naive Bayes.
1. Mô hình Gaussian Naive Bayes
Mô hình Gaussian Naive Bayes được sử dụng cho các thuộc tính liên tục với giả định sau:
- Các thuộc tính tuân theo phân phối chuẩn.
- Xác suất có điều kiện được tính theo công thức:
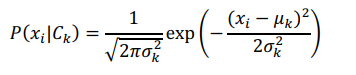
Trong đó μk và ![]() lần lượt là trung bình và phương sai của thuộc tính xi trong lớp Ck.
lần lượt là trung bình và phương sai của thuộc tính xi trong lớp Ck.
Ứng dụng: Phân loại dữ liệu liên tục như phân tích cảm xúc, nhận diện khuôn mặt, chẩn đoán y khoa.
2. Mô hình Multinomial Naive Bayes
Mô hình Multinomial Naive Bayes được sử dụng cho các thuộc tính rời rạc với giả định xác suất có điều kiện sau đây:
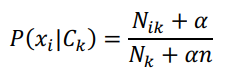
Trong đó:
- Nik: số lần từ xi xuất hiện trong lớp Ck.
- Nk: tổng số từ trong lớp Ck.
- α: hệ số làm trơn Laplace (thường là 1).
- n: tổng số đặc trưng (số lượng từ trong từ điển).
Ứng dụng: Phân loại văn bản, lọc spam, phân tích chủ đề.
3. Mô hình Bernoulli Naive Bayes
Mô hình Bernoulli Naive Bayes được sử dụng cho dữ liệu nhị phân và tuân theo xác suất có điều kiện sau đây:
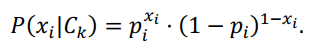
Ứng dụng: Lọc spam, phân loại văn bản (có hoặc không), nhận dạng mẫu đơn giản.
Ví dụ học có giám sát bằng mô hình Gaussian Naive Bayes trong R
Xét tập dữ liệu Iris Species.
Mục tiêu: Dự đoán đúng loài hoa dựa trên thông tin các thuộc tính.
Quá trình được thực hiện tuần tự qua các bước sau đây:
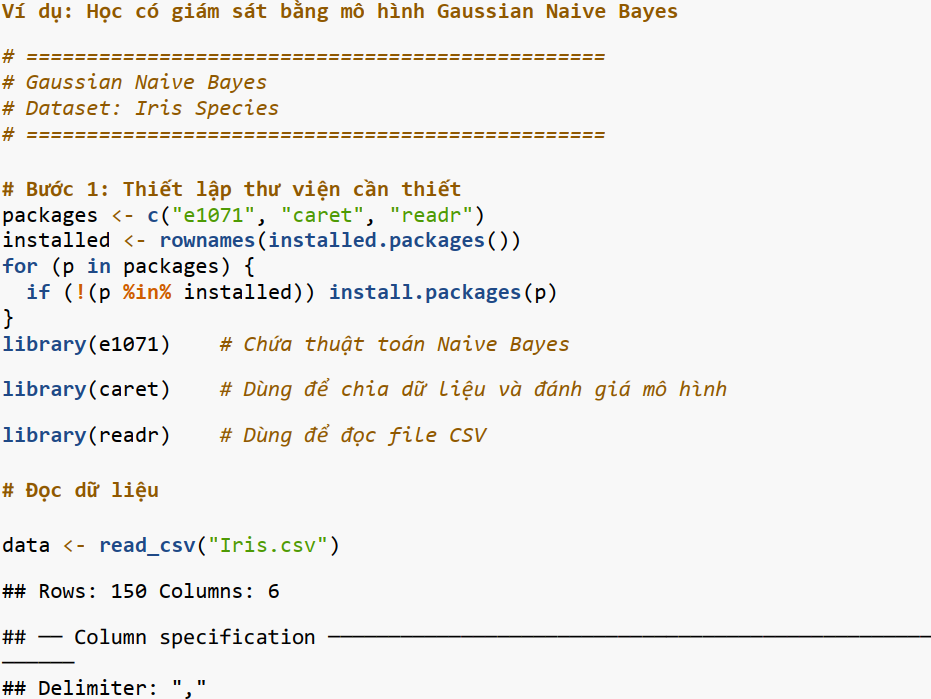
Bước 1: Cài đặt và thiết lập môi trường;
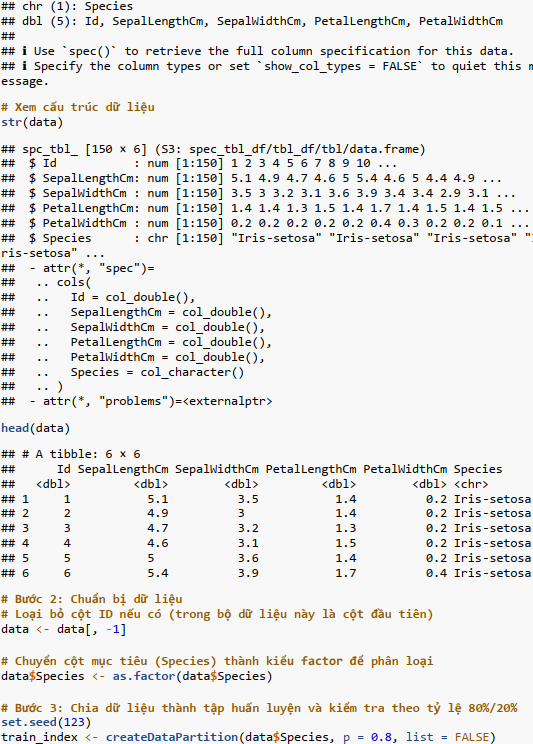
Bước 2: Chuẩn bị dữ liệu;
Bước 3: Chia dữ liệu thành tập huấn luyện và kiểm tra;
Bước 4: Huấn luyện mô hình Gaussian Naive Bayes;
Bước 5: Dự đoán nhãn trên tập kiểm tra;
Bước 6: Đánh giá mô hình bằng ma trận nhầm lẫn;
Bước 7: Kết quả đánh giá.
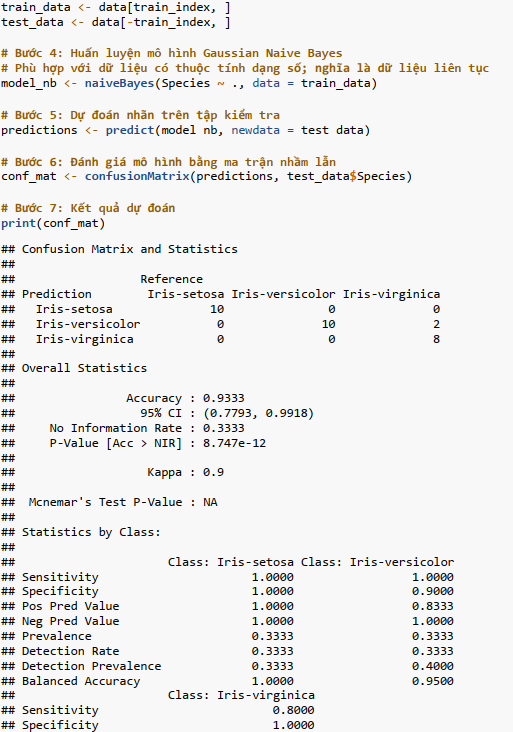

Diễn giải kết quả: Mô hình Gaussian Naive Bayes trên tập test có độ chính xác (accuracy) 93.33%.
Ví dụ học có giám sát bằng mô hình Bernoulli Naive Bayes trong R
Xét tập dữ liệu: Bank Marketing Dataset.
Mục tiêu: Dự đoán khả năng khách hàng đăng ký sản phẩm tiết kiệm có kỳ hạn qua cuộc gọi.
Quá trình được thực hiện tuần tự qua các bước sau đây:
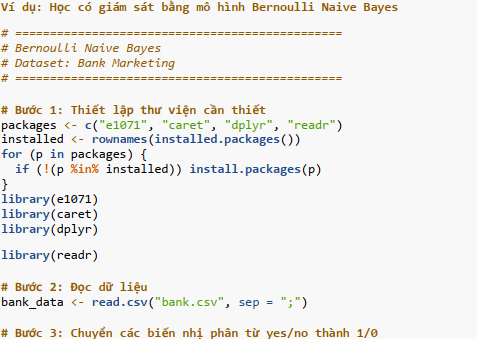
Bước 1: Cài đặt và thiết lập môi trường;
Bước 2: Chuẩn bị dữ liệu;
Bước 3: Chia dữ liệu thành tập huấn luyện và kiểm tra;
Bước 4: Huấn luyện mô hình Bernoulli Naive Bayes;
Bước 5: Dự đoán nhãn trên tập kiểm tra;
Bước 6: Đánh giá mô hình bằng ma trận nhầm lẫn;
Bước 7: Kết quả đánh giá.

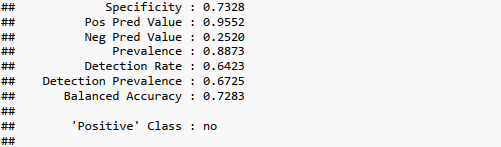
Diễn giải kết quả: Mô hình Bernoulli Naive Bayes trên tập test có độ chính xác (accuracy) 72.49%.
Kết Luận
Học có giám sát bằng mô hình Naive Bayes là một mô hình hoạt động đơn giản và hiệu quả; chúng dựa trên định lý xác suất Bayes với các giả định các đặc trưng độc lập. Mô hình phù hợp cho nhiều bài toán phân loại, đặc biệt là trong xử lý ngôn ngữ tự nhiên và dữ liệu nhiều chiều.
Nhất Luận
----------------------------------------
Tài liệu tham khảo:
[1] R for Data Science. https://r4ds.had.co.nz/
[2] R for Data Science (2e). https://r4ds.hadley.nz/
[3] R for Data Science. https://bookdown.org/swen/R_for_Data_Science/
[4] R Packages (2e). https://r-pkgs.org/
[5] Advanced R. https://adv-r.hadley.nz/index.html#license
[6] Advanced R Solutions. https://advanced-r-solutions.rbind.io/
[7] Machine Learning with R. https://tuanvanle.wordpress.com/2017/04/19/machine-learning-with-r/
[8] Trí tuệ nhân tạo. https://trituenhantao.io/kien-thuc/phan-1-phan-loai-naive-bayes-ly-thuyet/
[9] Iris Species. https://www.kaggle.com/datasets/uciml/iris
[10] Bank Marketing Dataset. https://www.kaggle.com/datasets/janiobachmann/bank-marketing-dataset?utm_source=chatgpt.com