Học không giám sát là quá trình huấn luyện dữ liệu mà không cần gán nhãn; dựa trên việc phân cụm hoặc liên kết. Các mô hình học không giám sát bao gồm: Hierarchical clustering, K-means clustering, K-NN (K Nearest Neighbors), PCA (Principal Component Analysis), Singular Value Decomposition, Independent Component Analysis và Association.
Học không giám sát bằng mô hình Hierarchical Clustering (phân cụm phân cấp)
Mô hình Hierarchical Clustering sử dụng phương pháp phân cụm không giám sát để xây dựng một cấu trúc phân cấp các cụm dưới dạng cây phân cấp; có hai loại phân cụm phân cấp:
- Mô hình phân cụm phân cấp từ dưới lên: bắt đầu với mỗi điểm dữ liệu là một cụm riêng lẻ, sau đó liên tục gộp các cụm gần nhau nhất cho đến khi tất cả dữ liệu được gom vào một cụm lớn hoặc đạt đến số cụm mong muốn.
- Mô hình phân cụm phân cấp từ trên xuống: bắt đầu với toàn bộ dữ liệu trong một cụm duy nhất, sau đó chia nhỏ cụm này thành các cụm con cho đến khi đạt được số cụm thỏa mãn điều kiện dừng.
Đặc điểm và quy trình của mô hình Hierarchical Clustering
- Không cần xác định trước số cụm: khác với các mô hình như K-means, mô hình phân cụm phân cấp không yêu cầu phải xác định số cụm ban đầu.
- Cây phân cấp: kết quả được biểu diễn dưới dạng cây phân cấp, qua đó dễ dàng trực quan để xác định số cụm phù hợp.
- Khoảng cách và liên kết: mô hình sử dụng các phép đo khoảng cách như Euclidean, Manhattan,… và các tiêu chí liên kết khác nhau như liên kết đơn, liên kết hoàn chỉnh, liên kết trung bình,… để quyết định cụm nào sẽ được gộp hoặc chia.
Ứng dụng của mô hình Hierarchical Clustering
Mô hình Hierarchical Clustering được ứng dụng trong:
- Phân loại tài liệu trong xử lý ngôn ngữ tự nhiên.
- Khám phá mẫu trong dữ liệu y tế, sinh học: phân nhóm gene, loài, phân loại bệnh nhân, phát hiện nhóm bệnh tương đồng mà không cần nhãn trước.
- Phân tích dữ liệu môi trường, địa lý: xác định các vùng ô nhiễm hoặc nhóm điểm dữ liệu có đặc điểm tương tự.
- Phân tích hình ảnh, phân nhóm khách hàng trong Marketing.
Ưu điểm và nhược điểm của mô hình Hierarchical Clustering
Ưu điểm của mô hình Hierarchical Clustering
- Không cần biết trước số cụm.
- Dễ dàng trực quan hóa kết quả qua cây phân cấp.
- Phù hợp với nhiều loại dữ liệu và khoảng cách khác nhau.
Nhược điểm của mô hình Hierarchical Clustering
- Tính toán phức tạp, không hiệu quả với tập dữ liệu rất lớn.
- Kết quả phụ thuộc nhiều vào phép đo khoảng cách và phương pháp liên kết.
- Không thể điều chỉnh lại các cụm sau khi gộp hoặc chia.
- Nhạy cảm với dữ liệu nhiễu.
Ví dụ học không giám sát bằng mô hình Hierarchical Clustering trong R
Xét tập dữ liệu UCI Heart Disease Data.
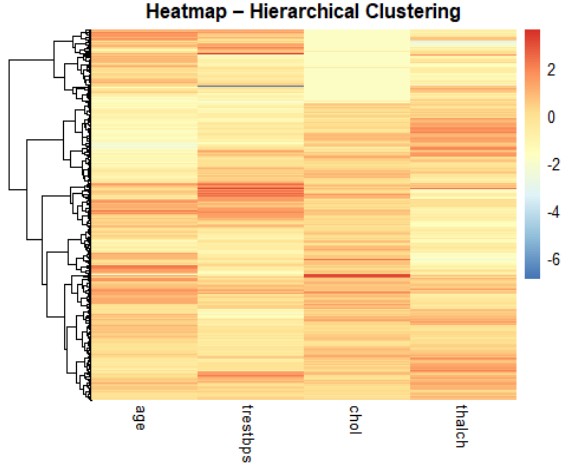
Mục tiêu: Phân loại bệnh nhân tim mạch dựa trên các thuộc tính sau:
- age: tuổi của bệnh nhân.
- trestbps: huyết áp tâm thu lúc nghỉ (resting blood pressure).
- chol: mức cholesterol huyết thanh (serum cholesterol).
- thalch: nhịp tim tối đa đạt được (maximum heart rate achieved).
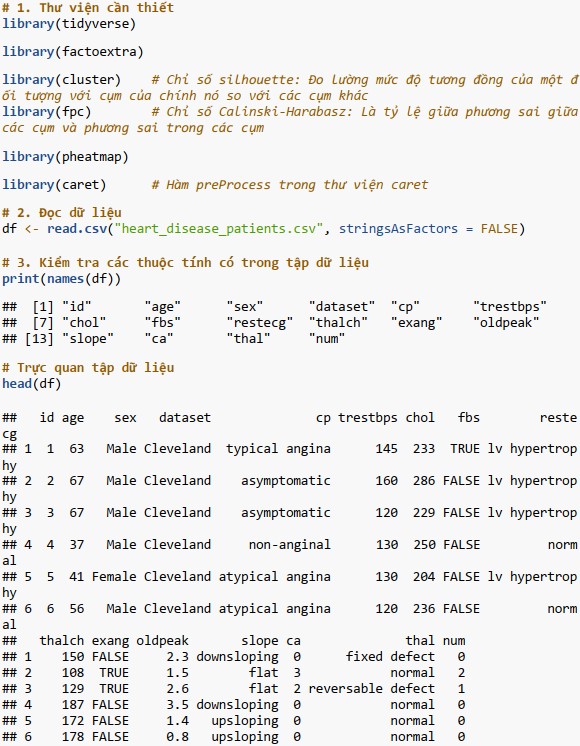
Quy trình được thực hiện tuần tự thông qua các bước sau đây:
Bước 1: Cài đặt và thiết lập môi trường;
Bước 2: Chuẩn bị dữ liệu;
Bước 3: Chọn thước đo khoảng cách (Distance Metric);
Bước 4: Xây dựng ma trận khoảng cách (Proximity Matrix);
Bước 5: Chọn phương pháp liên kết cụm (Linkage Method);
Bước 6: Áp dụng thuật toán phân cụm;
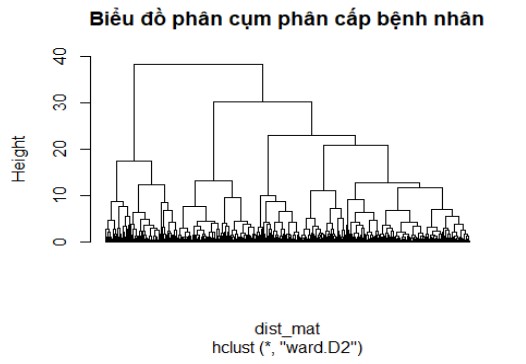
Bước 7: Vẽ và phân tích phân cụm phân cấp (Dendrogram);
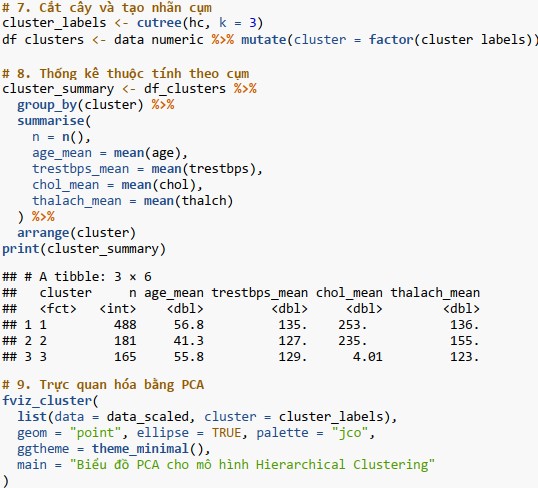
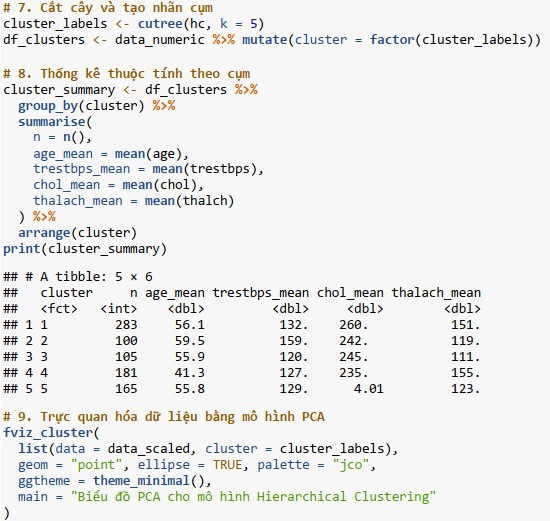
Bước 8: Cắt cây và gán nhãn cụm;
Bước 9: Phân tích thuộc tính từng cụm;
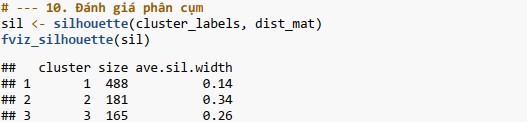
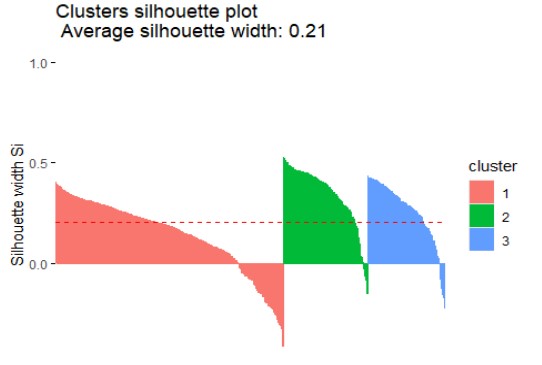
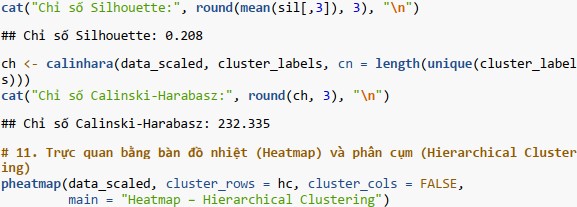
Bước 10: Đánh giá chất lượng phân cụm.
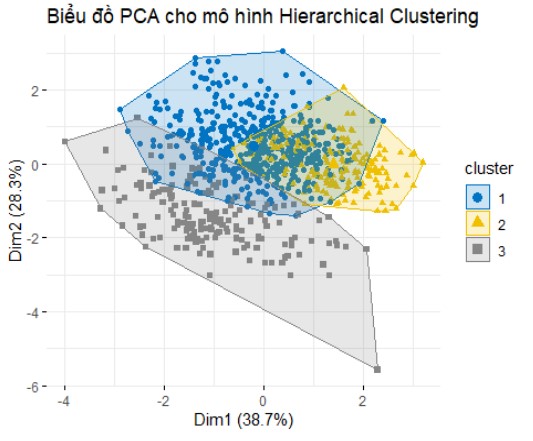
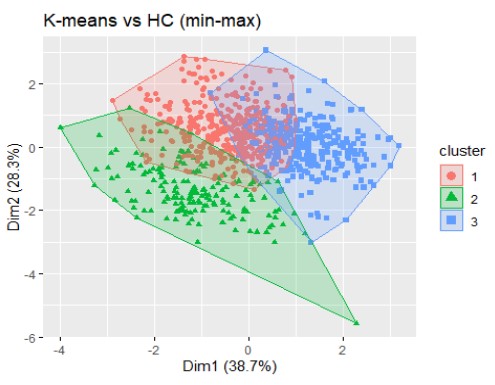
Ví dụ cho 3 nhóm:


Ví dụ: Phân thành 5 nhóm
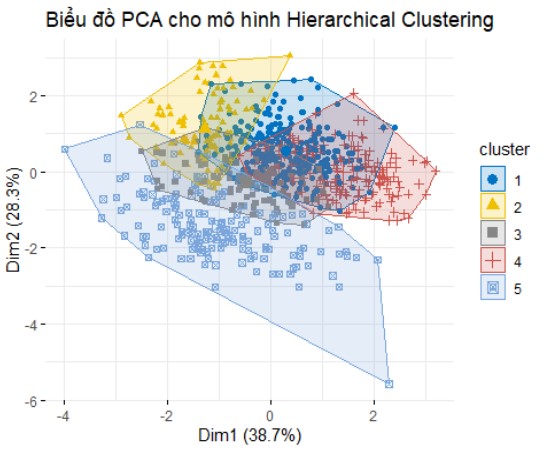

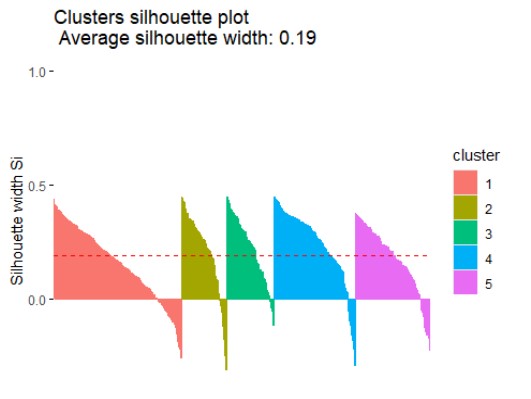
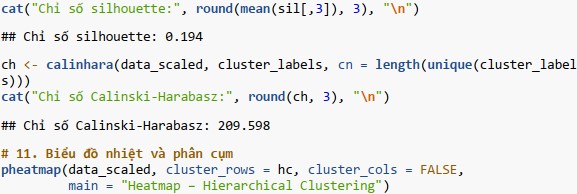
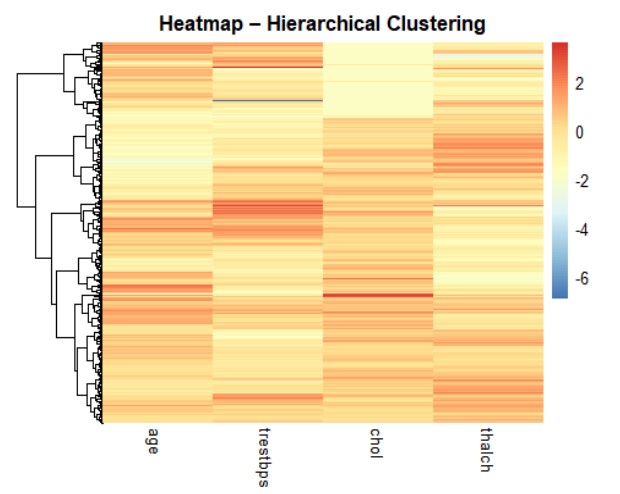

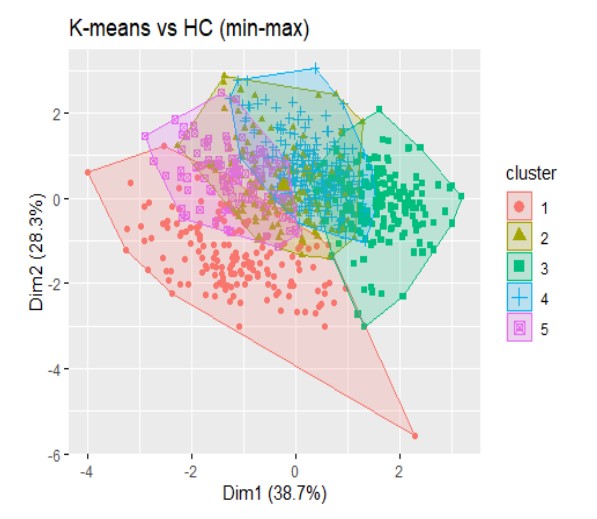
So sánh hai cách phân nhóm:
- Chỉ số Silhouette: với k=3 đạt 0.208, cao hơn một chút so với k=5 (0.194). Mặc dù cả hai giá trị đều tương đối thấp (cho thấy các cụm có thể không được tách biệt hoàn toàn rõ ràng và có thể có sự chồng chéo), nhưng k=3 cho thấy cấu trúc cụm có phần chặt chẽ và riêng biệt hơn.
- Chỉ số Calinski-Harabasz: với k=3 đạt 232.34, cao hơn đáng kể so với k=5 (209.60). Giá trị cao hơn của Calinski-Harabasz cho thấy các cụm được phân tách rõ ràng hơn và có tính đồng nhất cao hơn bên trong khi sử dụng 3 cụm.
Đánh giá kết quả: Phân cụm thành 3 nhóm cho thấy hiệu quả tốt hơn và tạo ra các cụm có cấu trúc rõ ràng, đồng nhất hơn so với việc chia thành 5 nhóm.
Kết Luận
Mô hình Hierarchical Clustering là một mô hình học không giám sát mạnh mẽ, giúp phân nhóm dữ liệu dựa trên cấu trúc phân cấp, hỗ trợ phát hiện các mẫu ẩn trong dữ liệu mà không cần thông tin nhãn trước, được ứng dụng đa dạng trong nhiều lĩnh vực nghiên cứu và thực tiễn.
Nhất Luận
----------------------------------------
Tài liệu tham khảo:
[1] R for Data Science. https://r4ds.had.co.nz/
[2] R for Data Science (2e). https://r4ds.hadley.nz/
[3] R for Data Science. https://bookdown.org/swen/R_for_Data_Science/
[4] R Packages (2e). https://r-pkgs.org/
[5] Advanced R. https://adv-r.hadley.nz/index.html#license
[6] Advanced R Solutions. https://advanced-r-solutions.rbind.io/
[7] Machine Learning with R. https://tuanvanle.wordpress.com/2017/04/19/machine-learning-with-r/
[8] UCI Heart Disease Data. https://www.kaggle.com/datasets/redwankarimsony/heart-disease-data