Trong thống kê mô tả, bên cạnh những con số cho biết các giá trị về mặt "trung tâm" hay "độ phân tán" của tập dữ liệu, ta cũng cần biết những đại lượng cũng như hình dạng mô tả tập dữ liệu đó. Ngoài 2 giá trị số thể hiện đặc trưng của hình dáng của phân phối: Độ lệch – Skewness và Độ nhọn – Kurtosis, biểu đồ Histogram thường được sử dụng để biểu diễn hình dáng phân phối cũng được giới thiệu qua bài viết này.
1. Biểu đồ Histogram
Biểu đồ Histogram là một dạng biểu đồ cột được sử dụng để mô tả trực quan sự phân bố tần suất cho tập dữ liệu. Theo nguyên tắc, biểu đồ Histogram thường được dùng cho tập dữ liệu từ 100 giá trị trở lên (Illowsky et al., 2013). Biểu đồ Histogram có thể cung cấp các thông tin:
- Trung tâm về mặt vị trí của tập dữ liệu;
- Độ phân tán của tập dữ liệu;
- Độ lệch của tập dữ liệu;
- Sự hiện diện của các giá trị ngoại lệ (outliers);
- Sự hiện diện của các yếu vị (mode) trong tập dữ liệu.
Các yếu tố này cung cấp dấu hiệu về mô hình phân phối thích hợp cho tập dữ liệu. Đối với một biến rời rạc, biểu đồ thường có một thanh riêng biệt cho mỗi giá trị. Đối với một biến liên tục, cần chia khoảng các giá trị thành các khoảng nhỏ, với các giá trị được nhóm lại với nhau. Cũng có thể thực hiện như vậy, khi một biến rời rạc có một lượng lớn các giá trị (chẳng hạn như điểm của một bài kiểm tra).
Ví dụ: Có một danh sách thống kê 756 người theo độ tuổi. Ta có thể muốn biết có bao nhiêu người theo từng nhóm tuổi (tức là có bao nhiêu trẻ em, thanh niên, trung niên, cao niên). Sự phân bố độ tuổi của nhóm người này được thực hiện bằng cách nhóm tất cả vào các biến phân tổ theo độ tuổi và sau đó đếm số người trong mỗi biến, ví dụ như bảng phân tổ theo 5 năm, như sau:

Bảng số liệu này cũng có thể biểu diễn trực quan với các hình chữ nhật có chiều cao tương ứng với số lượng và độ rộng tương ứng với phân tổ theo độ tuổi.
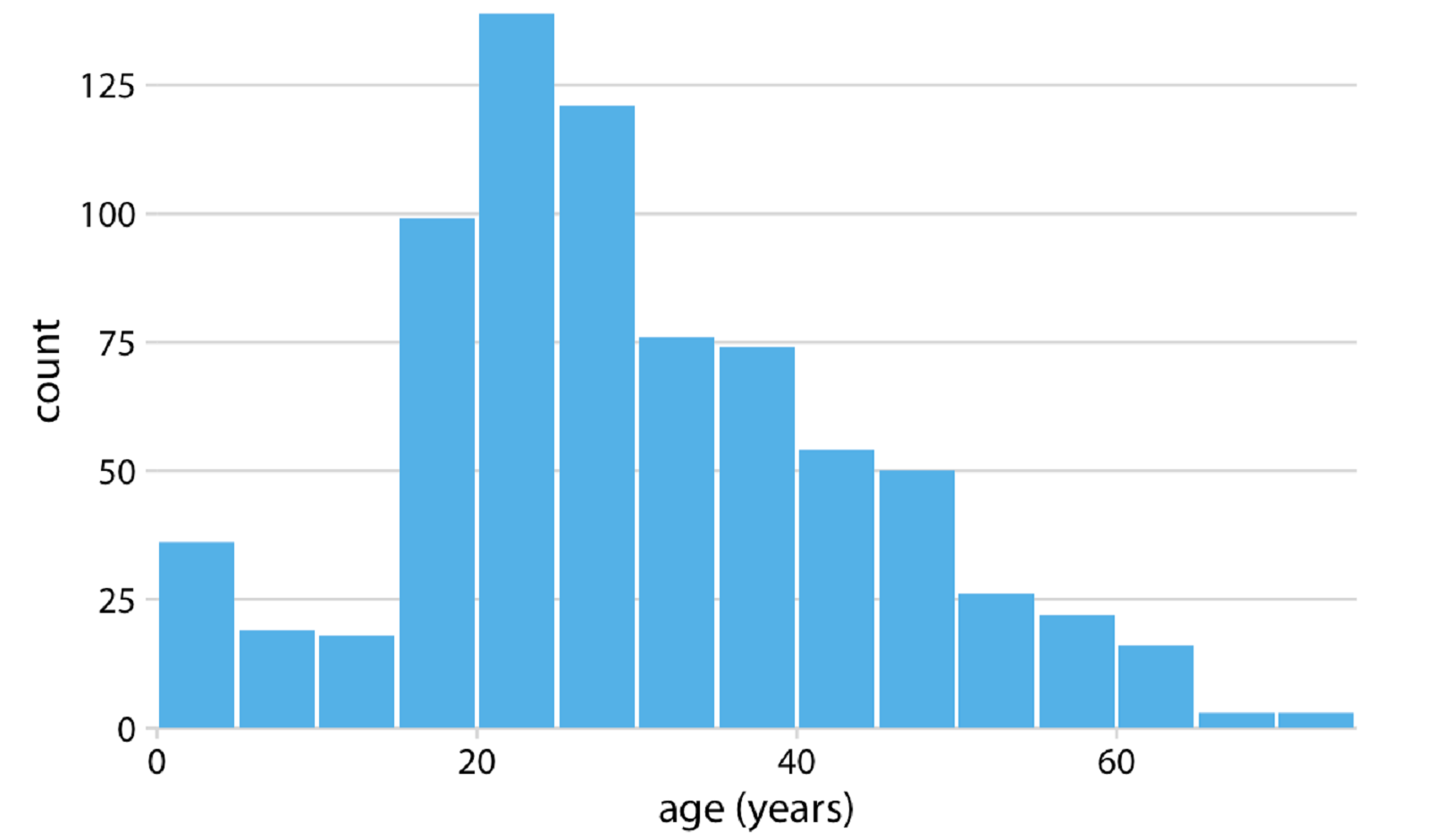 Nguồn: Fundamentals of Data Visualization
Nguồn: Fundamentals of Data Visualization
Biểu đồ Histogram được tạo ra bằng cách phân loại dữ liệu, hình thức trực quan chính xác của chúng phụ thuộc vào việc lựa chọn độ rộng cột tương ứng với cách phân tổ mà biến phân loại đang sử dụng.
Hầu hết các phần mềm trực quan hóa tạo biểu đồ sẽ chọn độ phân tổ theo mặc định, nhưng có thể đó không phải là phân tổ thích hợp nhất. Do đó, cần xác định cách phân tổ phù hợp với tập dữ liệu để kết quả trực quan phản ánh chính xác. Nếu độ rộng của phân tổ quá nhỏ thì biểu đồ sẽ xuất hiện nhiều đỉnh hơn và khó nhận thấy các xu hướng chính trong tập dữ liệu. Mặt khác, nếu phân tổ quá rộng thì các yếu tố nhỏ hơn trong phân phối dữ liệu, chẳng hạn như giảm khoảng 10 tuổi trong ví dụ này, có thể không nhìn thấy được.
Hình dưới đây là 4 cách phân tổ theo 1 năm (a), 3 năm (b), 5 năm (c) và 10 năm (d). Có thể thấy, phân tổ theo 1 năm quá nhỏ nhưng có thể giúp quan sát chính xác một số giá trị ngoại lệ ở 2 đầu, trong khi 10 năm quá rộng, còn 3-5 năm là mức phân tổ tối ưu hơn vừa có thể thấy rõ phân phối và độ lệch, cũng như các giá trị ngoại lệ[1] trong tập dữ liệu.
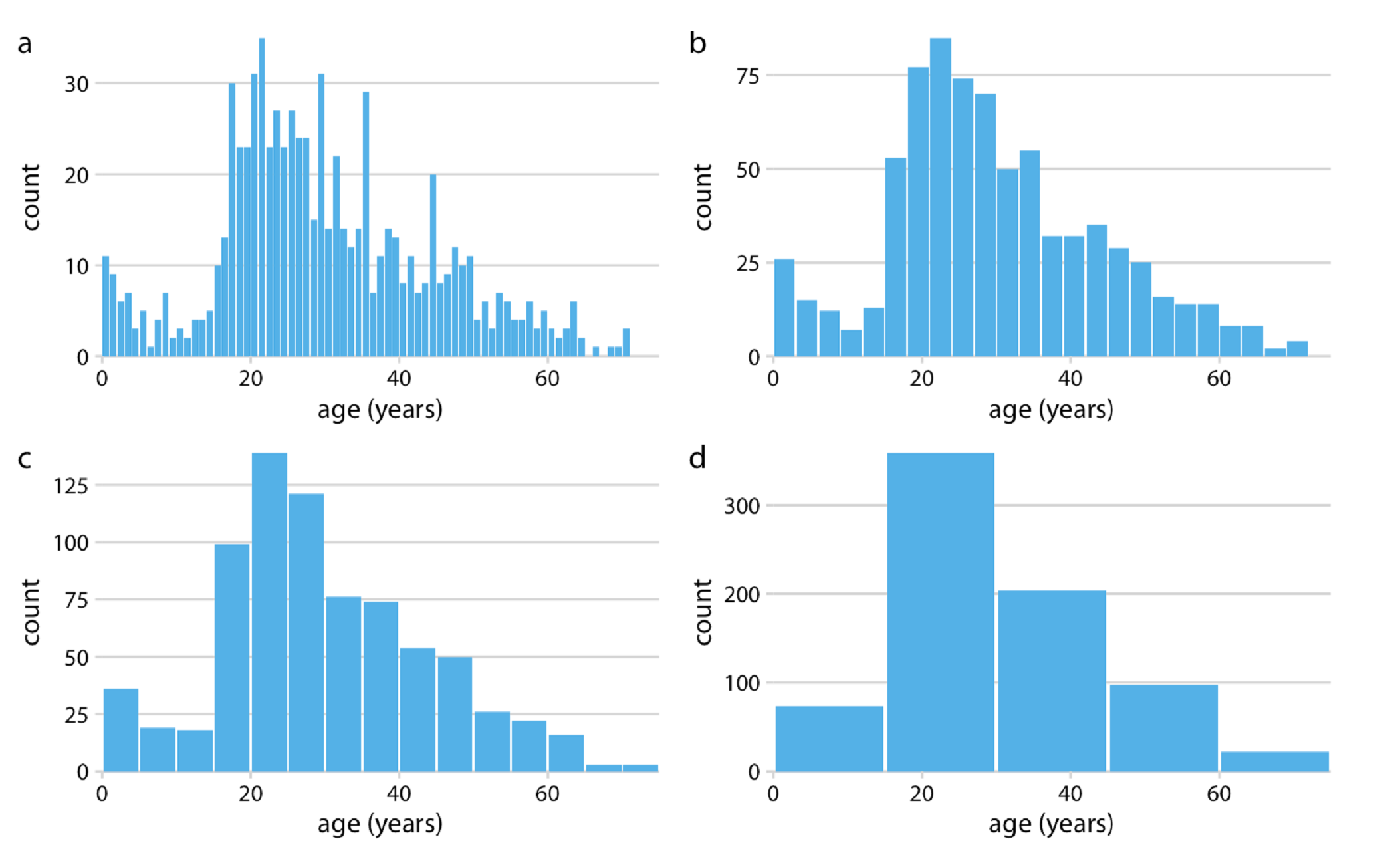 Nguồn: Fundamentals of Data Visualization
Nguồn: Fundamentals of Data Visualization
Trong phân tích dữ liệu, đặc biệt khi kiểm tra giả định phân phối chuẩn của phần dư trong mô hình hồi quy tuyến tính, biểu đồ Histogram thường được sử dụng. Nếu giá trị trung bình gần bằng 0, độ lệch chuẩn gần bằng 1, đường cong phân phối có dạng hình chuông, ta có thể khẳng định phân phối là xấp xỉ chuẩn, giả định phân phối chuẩn của phần dư không bị vi phạm.
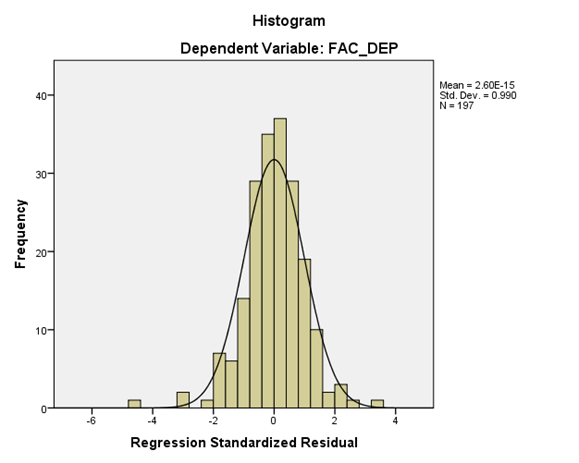
2. Giá trị số thể hiện đặc trưng của hình dáng của phân phối
Một nhiệm vụ cơ bản trong nhiều phân tích thống kê là xác định đặc điểm của vị trí và sự biến đổi của một tập dữ liệu. Tập dữ liệu có thể được phân phối theo nhiều cách, như trải rộng hơn ở bên trái hoặc bên phải hoặc trải đều. Độ lệch và độ nhọn là hai đại lượng số thể hiện đặc trưng của hình dáng phân phối và cung cấp nhiều thông tin hơn để đánh giá rủi ro hơn là chỉ sử dụng độ lệch chuẩn. Trong đó, biểu đồ Histogram là một kỹ thuật đồ họa hiệu quả để biểu diễn 2 đại lượng này.
ĐỘ LỆCH
Độ lệch (skewness) là thước đo mức độ đối xứng, bất đối xứng của một phân phối. Một phân phối, hoặc tập dữ liệu được xem là đối xứng nếu nó giống nhau ở bên trái và bên phải điểm trung tâm.
– Độ lệch có nhiều cách tính khác nhau:
- Đối với dữ liệu đơn biến x1, x2, ..., xN, công thức dưới đây được gọi là độ lệch Fisher-Pearson (Fisher-Pearson coefficient of skewness)
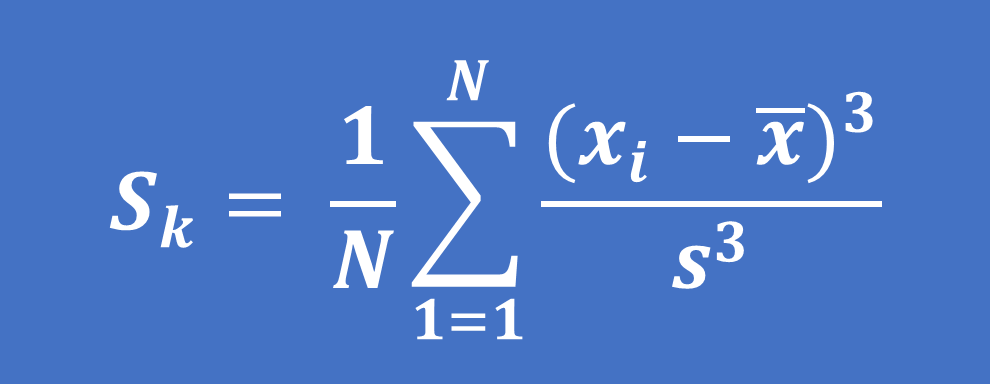
Trong đó: x ̅ là giá trị trung bình, s là độ lệch chuẩn và N là số điểm dữ liệu
Lưu ý: khi tính toán hệ số skewness, s được tính bằng N ở mẫu số thay vì N-1.
- Công thức tính độ lệch Galton (còn được gọi là độ lệch của Bowley) theo các giá trị của tứ phân vị như sau:
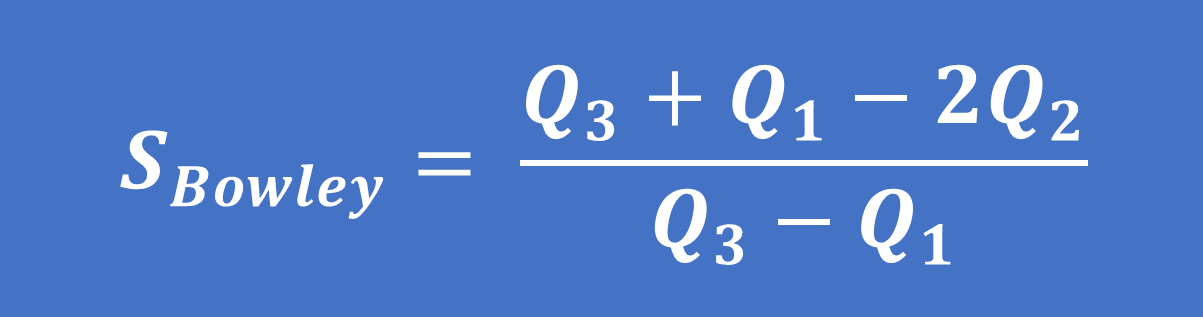
Trong đó Q1 là tứ phân vị thứ nhất (hay phân vị dưới), Q3 là tứ phân vị thứ 3 (hay phân vị trên) và Q2 là trung vị.
- Công thức tính độ lệch đơn giản do Karl Pearson đề xuất theo yếu vị (SPearson 1) và trung vị (SPearson 2) như sau:
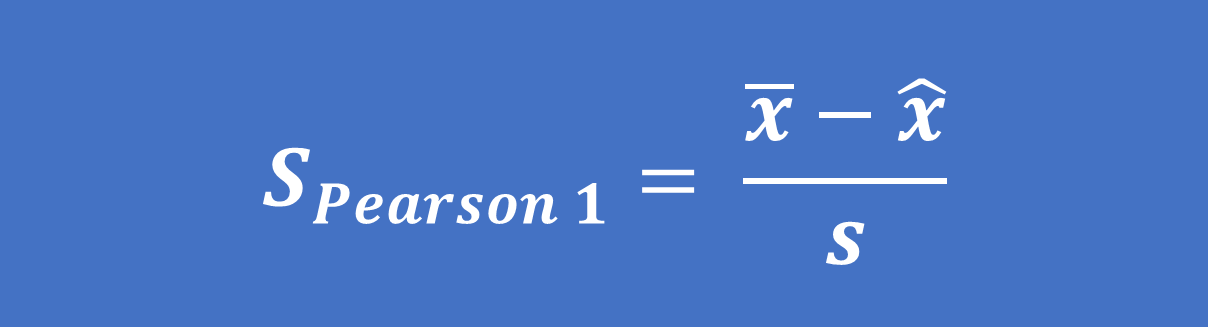
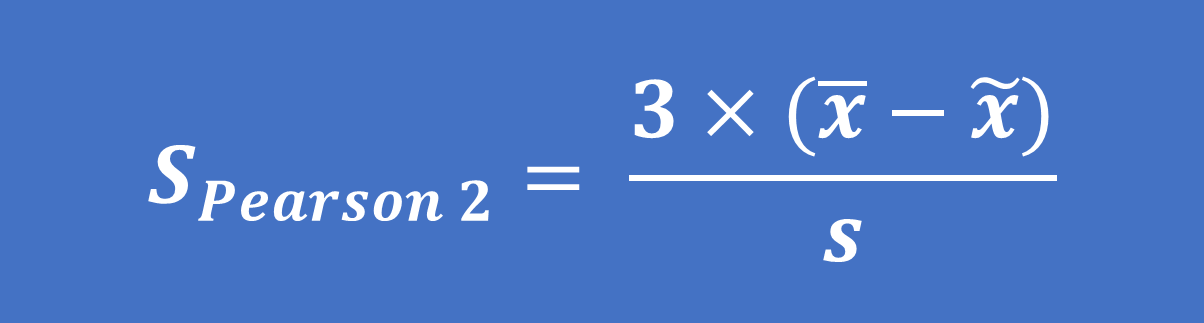
Trong đó: x ̅ là giá trị trung bình, x ̂ là yếu vị, x ̃ là trung vị, s là độ lệch chuẩn
– Biểu diễn trực quan độ lệch thông qua đồ thị:
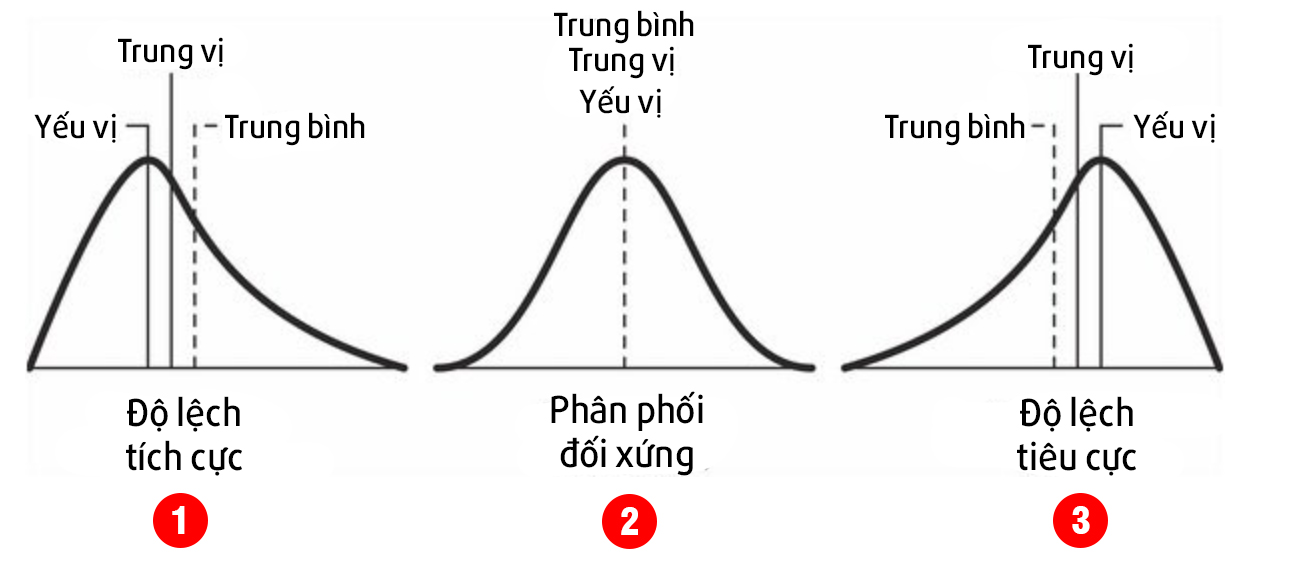
Hình trên cho thấy 3 tình huống xảy ra khi quan sát độ lệch được biểu diễn bằng đồ thị:
- Giá trị trung bình > Giá trị trung vị: lúc này Sk>0, được gọi là độ lệch tích cực hay Positive Skewness): đuôi bên PHẢI dài hơn đuôi bên trái; giá trị LỚN (outliers) đẩy giá trị trung bình về phía CUỐI (Ví dụ như đo lường thu nhập cá nhân, điều này chỉ ra 1 số ít người thu nhập quá cao trong tập dữ liệu)
- Giá trị trung bình = Giá trị trung vị = Yếu vị: lúc này Sk=0, được gọi là phân phối đối xứng hay Symetrical distribution
- Giá trị trung bình < Giá trị trung vị: lúc này Sk<0, được gọi là độ lệch tiêu cực hay Negative Skewness): đuôi bên TRÁI dài hơn đuôi bên phải; giá trị NHỎ (outliers) đẩy mean về phía ĐẦU
Lưu ý: Độ lệch không liên quan trực tiếp đến mối quan hệ giữa giá trị trung bình và giá trị trung vị: một phân phối với độ lệch âm có thể có giá trị trung bình lớn hơn hoặc nhỏ hơn giá trị trung vị và tương tự đối với độ lệch dương.
– Ứng dụng trong phân tích dữ liệu
- Độ lệch là một đại lượng thống kê mô tả được sử dụng kết hợp với biểu đồ để mô tả phân phối của tập dữ liệu.
- Nhiều mô hình giả định phân phối chuẩn, có nghĩa là dữ liệu đối xứng 2 bên giá trị trung bình (Phân phối chuẩn có độ lệch bằng 0). Nhưng trong thực tế, các điểm dữ liệu có thể không đối xứng hoàn toàn. Vì vậy, sự hiểu biết về độ lệch của tập dữ liệu sẽ cho biết liệu độ lệch so với giá trị trung bình là tích cực hay tiêu cực.
ĐỘ NHỌN
Độ nhọn (kurtosis) là là một đại lượng thống kê mô tả đo mức độ tập trung của các quan sát ở phần đuôi hoặc đỉnh của phân phân phối. Đỉnh là phần cao nhất của phân phối và đuôi là phần cuối của phân phối. Các tập dữ liệu có hệ số kurtosis cao có xu hướng dữ liệu tập trung về phần đuôi hoặc phần dữ liệu ngoại lệ, các tập dữ liệu có hệ số kurtosis thấp có xu hướng dữ liệu tập trung quanh vị trí trung tâm và có thể không có dữ liệu ngoại lệ.
– Công thức tính độ nhọn như sau:
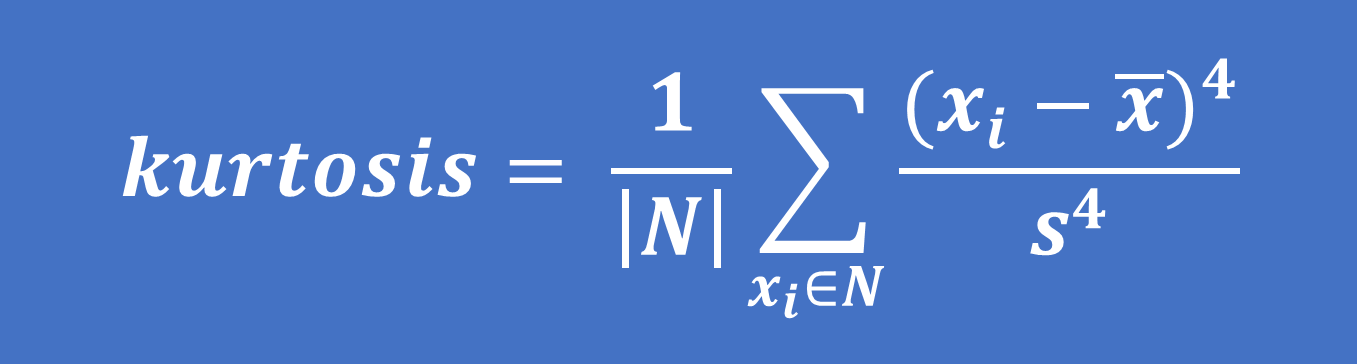
Trong đó: x ̅ là giá trị trung bình, s là độ lệch chuẩn và N là số điểm dữ liệu
Lưu ý: khi tính toán hệ số kurtosis, s được tính bằng N ở mẫu số thay vì N-1.
Hệ số kurtosis cho phân phối chuẩn nếu tính theo công thức trên sẽ là 3. Tuy nhiên, trong nhiều phần mềm tính toán, quy ước tính hệ số có thể sẽ khác nhau. Vì lý do này, một số nguồn sử dụng công thức sau để tính hệ số kurtosis (thường được gọi là "excess kurtosis"):
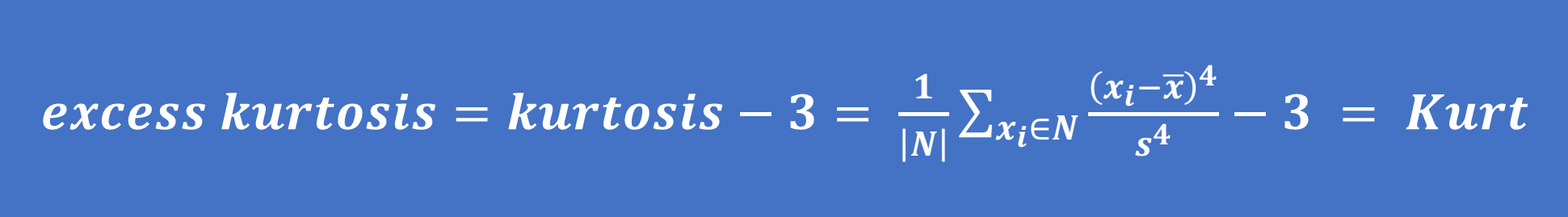
Khi đó, hệ số kurtosis cho phân phối chuẩn sẽ có giá trị là 0. Quy ước này được sử dụng để giải thích cho các nội dung tiếp theo.
Hệ số Kurt dương cho biết tập dữ liệu phân bố "theo đuôi nặng" (heavy-tailed) và hệ số Kurt âm cho biết phân bố "theo đuôi nhẹ" (light-tailed) và được chia thành 3 loại: Mesokurtic, Leptokurtic và Platykurtic tương ứng với 3 trường hợp xảy ra được biểu diễn như đồ thị bên dưới:
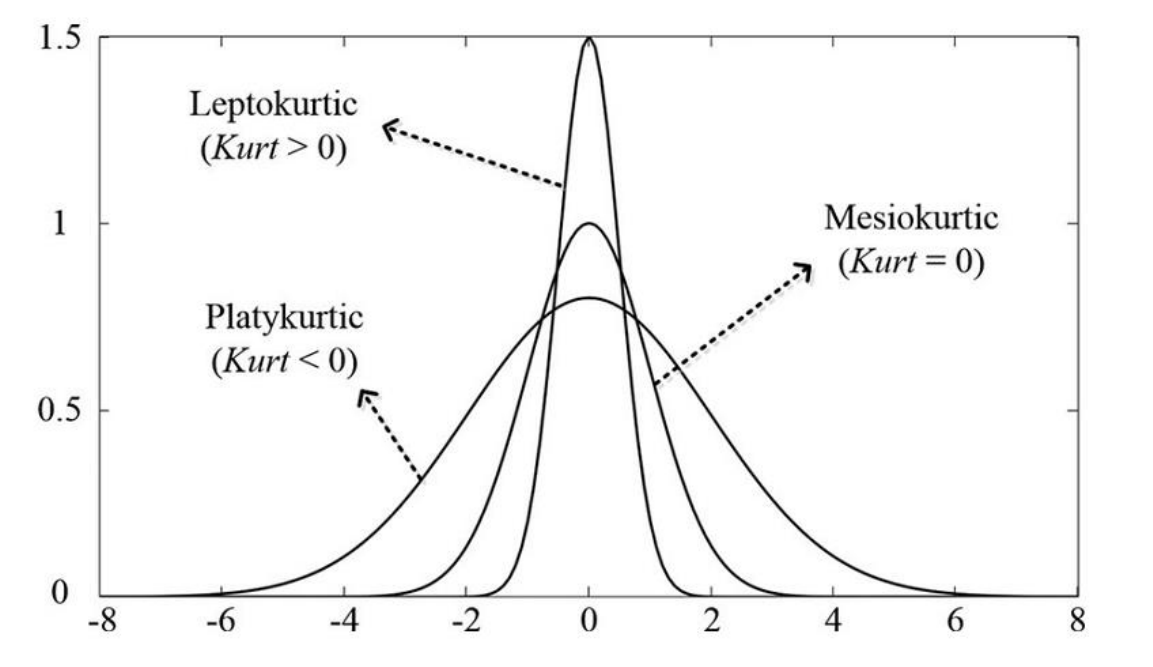
- Mesokurtic (Hệ số Kurt = 0): phân phối này có chiều rộng và đường cong vừa phải với chiều cao đỉnh trung bình, tương ứng với phân phối chuẩn. Hệ số Kurt của Mesokurtic không cao cũng không thấp, thay vào đó nó được coi là đường cơ sở cho hai cách phân loại Platykurtic và Leptokurtic
- Platykurtic (Hệ số Kurt < 0): "Platy-" có nghĩa là "rộng", phân phối này là một đường cong có đỉnh phẳng và đuôi mỏng hơn tức nhiều điểm phân tán hơn. Hệ số Kurt của Platykurtic phẳng hơn khi so sánh với phân phối chuẩn.
- Leptokurtic (Hệ số Kurt > 0): "Lepto-" có nghĩa là "mảnh mai", phân phối này có đỉnh cao hơn và đuôi to hơn so với phân phối chuẩn.
– Ứng dụng trong phân tích dữ liệu
Hệ số kurtosis là một thước đo hữu ích để đánh giá có những vấn đề nào liên quan đến các giá trị ngoại lệ trong tập dữ liệu hay không. Hệ số kurtosis lớn (trường hợp Leptokurtic) cho thấy tập dữ liệu gặp vấn đề nghiêm trọng đối với các giá trị ngoại lệ và có thể khiến nhà nghiên cứu lựa chọn các phương pháp thống kê thay thế.
Duy Sang tổng hợp
----------------------------------------
Tài liệu tham khảo:
Agresti A., Franklin C. (2013). Exploring Data with Graphs and Numerical Summaries. In F. C. Agresti A., Statistics: The Art and Science of Learning from Data (pp. 23-88). Pearson.
Evans, J. R. (2017). Business Analytics. Pearson.
Illowsky et al. (2013). Introductory Statistics. Houston: OpenStax.
Wikipedia. (2021, April 20). Kurtosis. Retrieved from Wikipedia: https://en.wikipedia.org/wiki/Kurtosis
Wikipedia. (2021, May 7). Skewness. Retrieved from Wikipedia: https://en.wikipedia.org/wiki/Skewness
Wilke, C. O. (2019). Fundamentals of Data Visualization. O’Reilly Media.
----------------------------------------
Các bài viết liên quan:
Thống kê mô tả trong nghiên cứu – Các đại lượng về trung tâm
Thống kê mô tả trong nghiên cứu – Các đại lượng về độ phân tán
Thống kê mô tả trong nghiên cứu – Các đại lượng về sự tương quan
---------------------------------------------------------------------------------------------------