Trong quá trình phân tích thống kê, khi muốn xác định mối quan hệ giữa hai biến ngẫu nhiên, chẳng hạn như giá cả có ảnh hưởng như thế nào đến lợi nhuận, hay chất lượng sản phẩm tác động ra sao đến sự hài lòng của khách hàng,..., ta cần có thước đo để tính toán sự liên kết giữa các biến này với nhau. Hai đại lượng phổ biến được sử dụng để đo lường mức độ tương quan là Hiệp phương sai (Covariance) và Hệ số tương quan Pearson (Pearson Correlation).
Cả hai thuật ngữ đều đo lường mối quan hệ và sự phụ thuộc giữa hai biến, trong đó “Covariance” cho biết xu hướng của mối quan hệ tuyến tính giữa các biến (tức mối quan hệ thuận hay nghịch), còn “Correlation” đo cả độ mạnh và xu hướng của mối quan hệ tuyến tính giữa hai biến. Điều khiến hai đại lượng trên có sự phân biệt là do các giá trị “Correlation” được chuẩn hóa, trong khi các giá trị “Covariance” thì không. Bài viết sau sẽ giới thiệu chi tiết về cách tính, ví dụ minh họa và các trường hợp sử dụng đối với từng đại lượng.
1. Hiệp phương sai (Covariance)
Hiệp phương sai (Covariance) là thước đo mối liên hệ tuyến tính giữa hai biến ngẫu nhiên X và Y, ký hiệu cov(X,Y). Về mặt tính toán, hiệp phương sai của một tập hợp là giá trị trung bình của các tích số sai lệch của mỗi lần quan sát. Giống như phương sai (Variance), hiệp phương sai cũng có 2 công thức khác nhau được sử dụng cho quần thể và mẫu.
– Công thức tính hiệp phương sai:
Đối với quần thể:
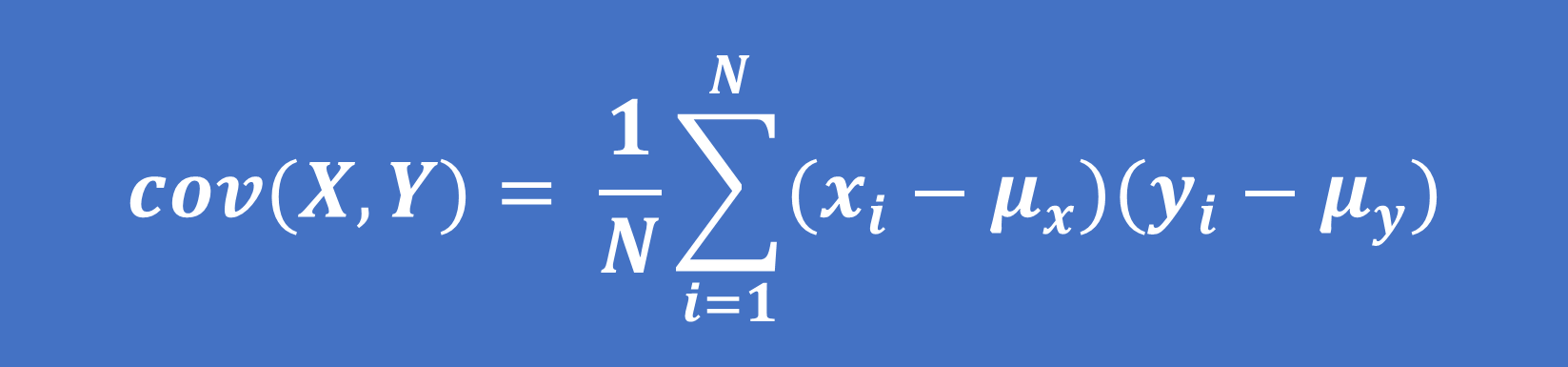 (1)
(1)
Đối với mẫu:
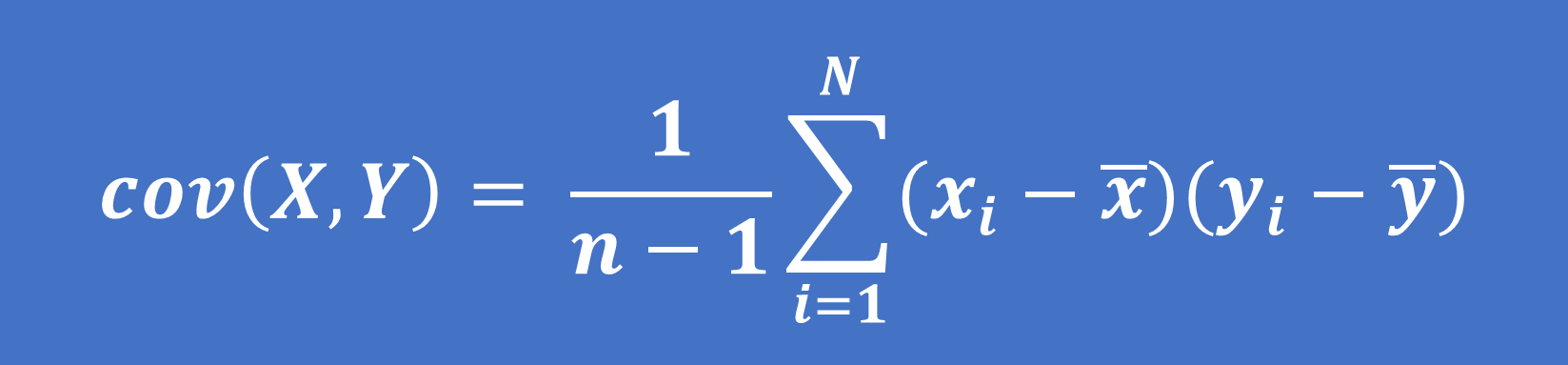 (2)
(2)
Trong đó: xi , yi là giá trị của quan sát thứ i
μx , μy là giá trị trung bình của tổng thể
x ̅ , y ̅ là giá trị trung bình của mẫu
N là tổng số quan sát của quần thể
n là tổng số quan sát của mẫu
– Trực quan bằng đồ thị:
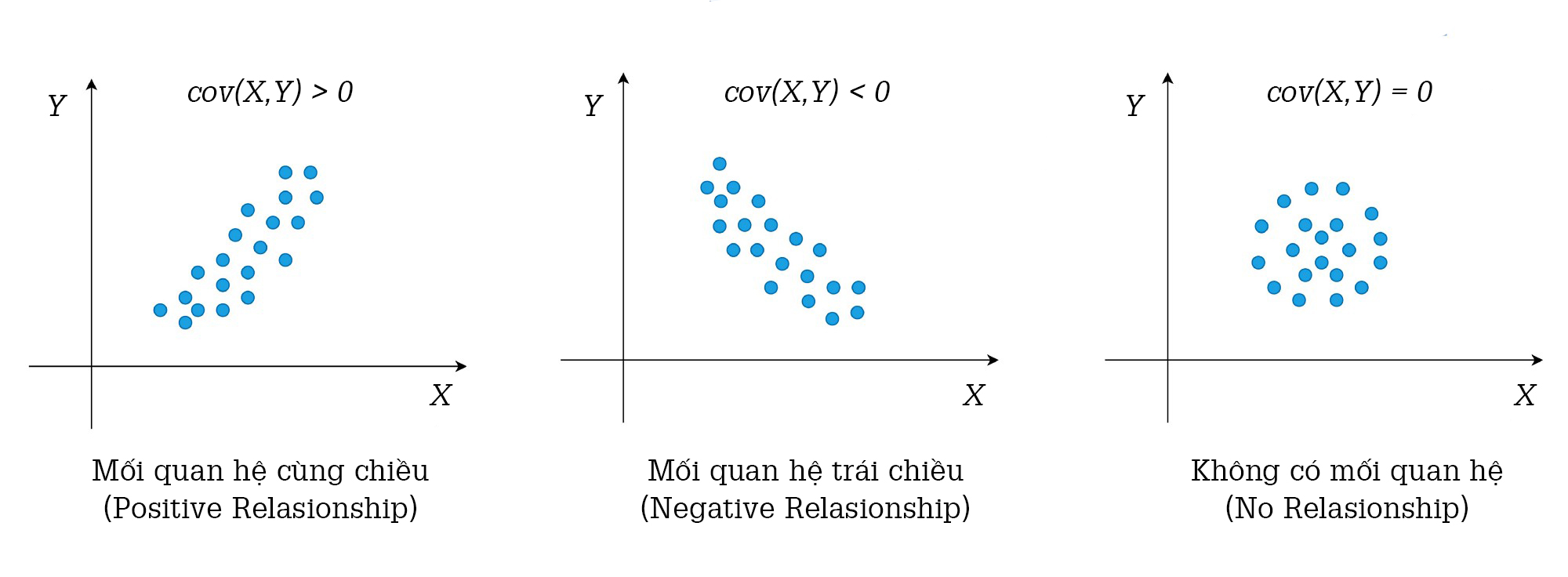
Đồ thị cho biết 3 trường hợp xảy ra khi tính hiệp phương sai:
- Khi cov(X,Y)>0: 2 biến X và Y có quan hệ tuyến tính thuận, X tăng, Y tăng.
- Khi cov(X,Y)<0: 2 biến X và Y có quan hệ tuyến tính nghịch, X tăng, Y giảm và ngược lại.
- Khi cov(X,Y)=0: 2 biến X và Y không có mối quan hệ với nhau.
– Ví dụ: Bộ dữ liệu về tỷ lệ tốt nghiệp và điểm SAT (tính bằng giá trị trung vị) của 49 trường đại học và cao đẳng của Mỹ được cho trong bảng sau:
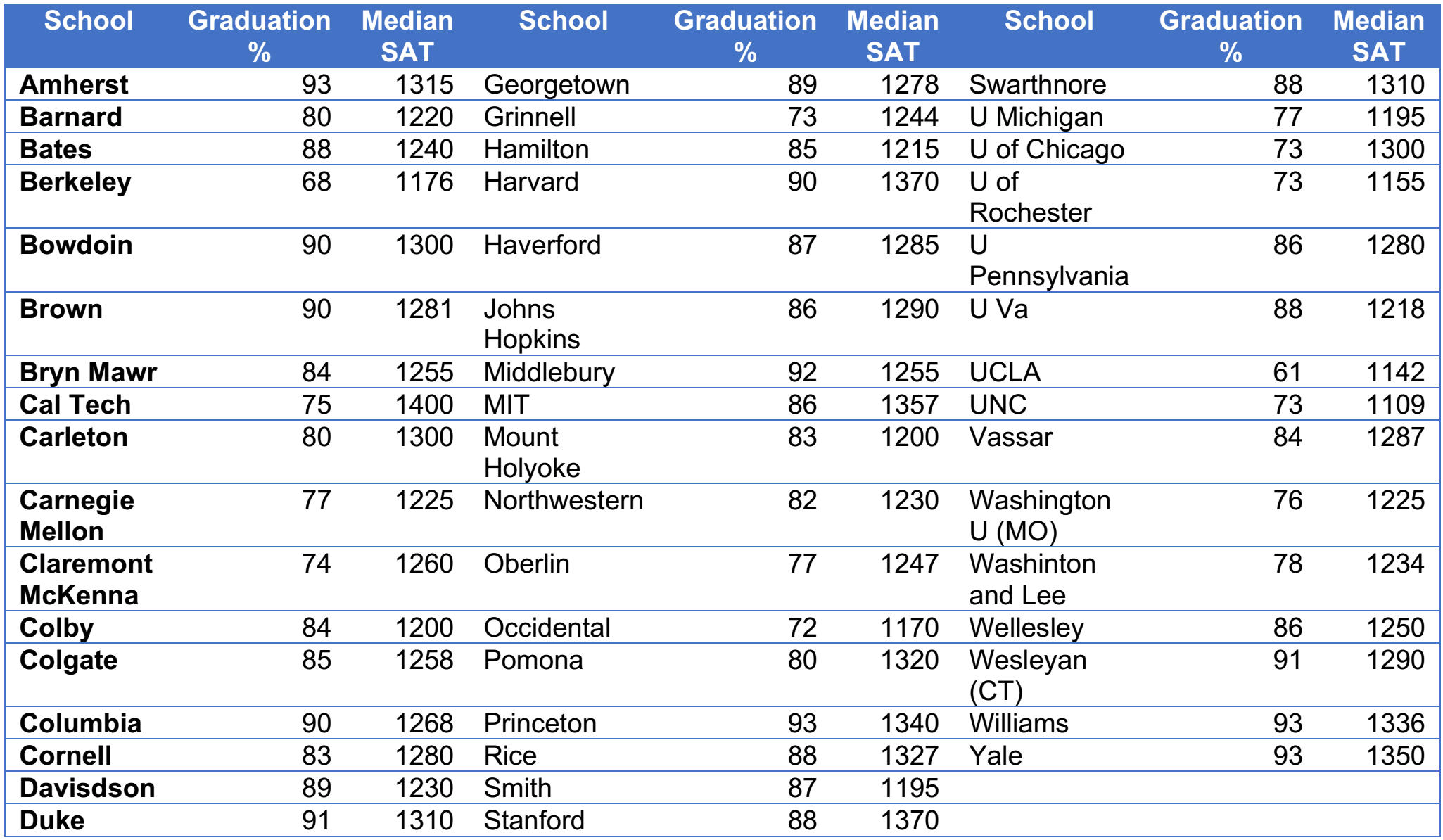
Nguồn dữ liệu: Colleges and Universities (Business Analytics, 2017)
Trực quan dữ liệu trên bằng đồ thị:
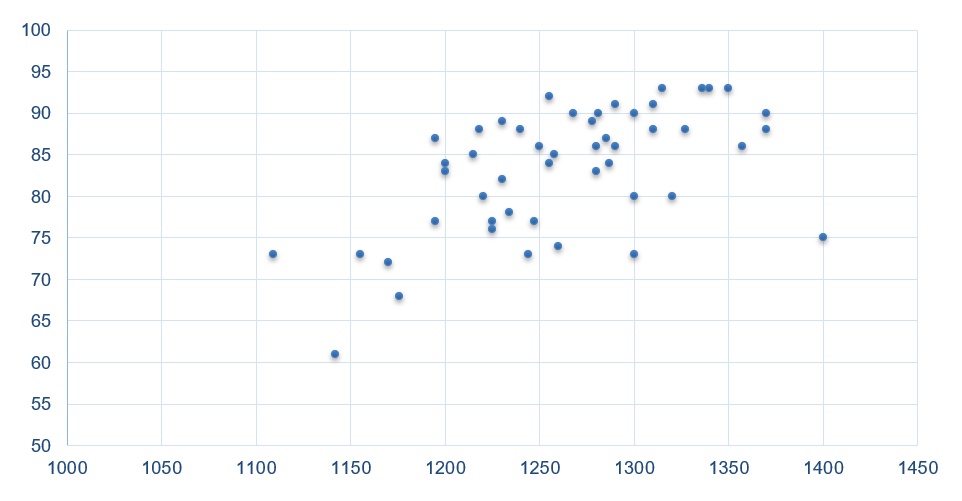
Đồ thị cho thấy mối quan hệ cùng chiều của 2 biến Median SAT (X) Graduation % (Y). Do đó, gía trị hiệp phương sai của 2 biến X và Y được kỳ vọng sẽ nhận giá trị > 0.
Có 2 cách để tính hiệp phương sai:
- Tính riêng từng giá trị (xi – x ̅ ) và (yi – y ̅ ), sau đó sử dụng công thức (2)
- Sử dụng hàm Excel tính hiệp phương sau đối với mẫu: COVARIANCE.S(array1, array2)
Kết quả: cov(X,Y)= 263,37
– Ma trận hiệp phương sai (Covariance matrix)
Hiệp phương sai chỉ có thể được tính cho giá trị giữa hai biến. Do đó, ma trận hiệp phương sai có vai trò đại diện cho các giá trị hiệp phương sai của từng cặp biến trong dữ liệu đa biến. Ma trận hiệp phương sai của tập hợp n biến ngẫu nhiên là một ma trận vuông. Ví dụ với 3 biến x,y,z được minh họa như sau:
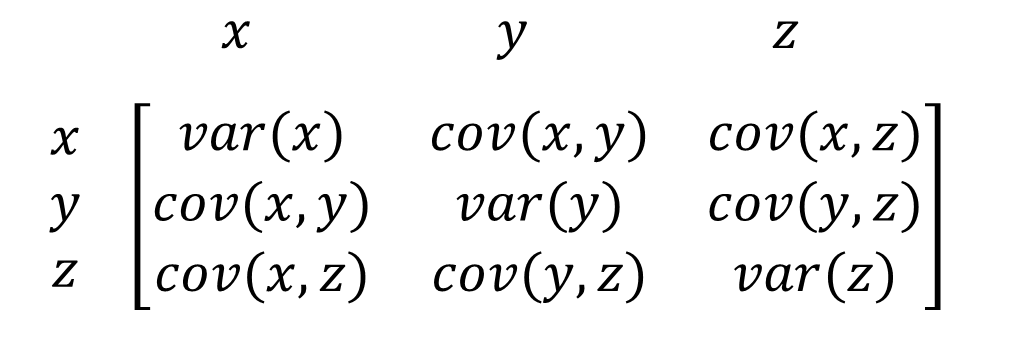
Các phần tử nằm trên đường chéo lần lượt là phương sai tương ứng của các biến này, trong khi các phần tử còn lại là các hiệp phương sai của từng cặp hai biến ngẫu nhiên khác nhau, trong tập hợp.
– Lưu ý:
- Hiệp phương sai sử dụng với các biến định lượng và có cùng thang đo.
- Giá trị số của hiệp phương sai không được chuẩn hóa, nên rất khó giải thích cường độ của mối quan hệ, vì nó phụ thuộc vào các đơn vị đo lường của các biến. Do đó, đối với dữ liệu khác thang đo, chỉ nên sử dụng để xem xu hướng của mối quan hệ là thuận hay nghịch.
Ví dụ khi xem xét mối quan hệ giữa chiều cao (cm) và cân nặng (kg)
Hcm= {162, 165, 168} Wkg = {50, 56, 60}
Ta có: cov(Hcm, Wkg) = 15
Khi thay đổi đơn vị: chiều cao (cm ->inch) và cân nặng (kg ->lb)
Hinch = Hcm/2,54 Wlb = Wkgx 2,2
Ta có: cov(Hinch, Wlb) = 12,99
Kết quả trên cho thấy sự tương quan thuận của chiều cao và cân nặng thông qua cov>0, không xác định được độ mạnh của tương quan, khi đổi đơn vị đo thì cov cũng thay đổi.
– Một số ứng dụng của hiệp phương sai và ma trận hiệp phương sai: (Wikipedia, 2021)
- Trong di truyền học, hiệp phương sai là cơ sở để tính toán Ma trận mối quan hệ di truyền (GRM) cho phép suy luận về cấu trúc quần thể từ mẫu không có họ hàng gần, cũng như suy luận về khả năng di truyền của các tính trạng[1] phức tạp.
- Trong thuyết tiến hóa và chọn lọc tự nhiên, phương trình Price sử dụng hiệp phương sai giữa đặc điểm và tính trạng để đưa ra mô tả toán học về quá trình tiến hóa và chọn lọc tự nhiên. Nó cung cấp một phương pháp để hiểu những tác động mà truyền gen và chọn lọc tự nhiên có đối với tỷ lệ gen trong mỗi thế hệ mới của quần thể.
- Trong kinh tế tài chính, hiệp phương sai được sử dụng trong lý thuyết danh mục đầu tư hiện đại và trong mô hình định giá tài sản vốn.
- Trong đồng hóa dữ liệu khí tượng và hải văn, ma trận hiệp phương sai rất quan trọng trong việc ước tính các điều kiện ban đầu cần thiết để chạy các mô hình dự báo thời tiết, một quy trình được gọi là đồng hóa dữ liệu[2].
- Trong xử lý tín hiệu, ma trận hiệp phương sai được sử dụng để nắm bắt sự biến thiên phổ của tín hiệu.
- Trong thống kê và xử lý hình ảnh, ma trận hiệp phương sai được sử dụng trong phân tích thành phần chính[3] để giảm kích thước đặc trưng trong quá trình tiền xử lý dữ liệu.
2. Hệ số tương quan Pearson (Pearson Correlation)
Độ tương quan (Correlation) là thước đo mối quan hệ tuyến tính giữa hai biến và không phụ thuộc vào các đơn vị đo lường của hai biến này. Độ tương quan được đo bằng hệ số tương quan, trong đó Hệ số tương quan momen sản phẩm Pearson (Pearson product-moment correlation coefficient – PPMCC) hay Hệ số tương quan Pearson là thước đo quen thuộc nhất về sự phụ thuộc giữa hai biến.
Hệ số tương quan Pearson của 2 biến ngẫu nhiên X,Y, ký hiệu ρxy , được tính bằng cách chia hiệp phương sai cho tích của độ lệch chuẩn. Độ lệch chuẩn đo lường độ biến thiên tuyệt đối của tập dữ liệu, do đó khi chia các giá trị hiệp phương sai cho độ lệch chuẩn, nó sẽ chia tỷ lệ giá trị xuống một phạm vi giới hạn từ –1 đến +1. Đây chính là phạm vi của các giá trị tương quan.
– Công thức tính hệ số tương quan Pearson:
Đối với quần thể:
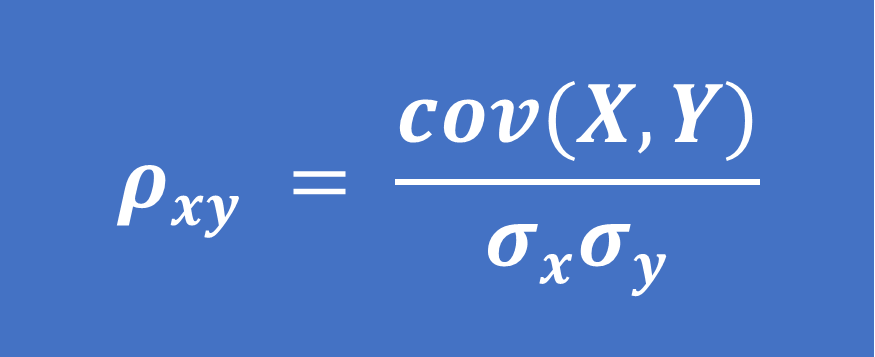 (3)
(3)
Đối với mẫu:
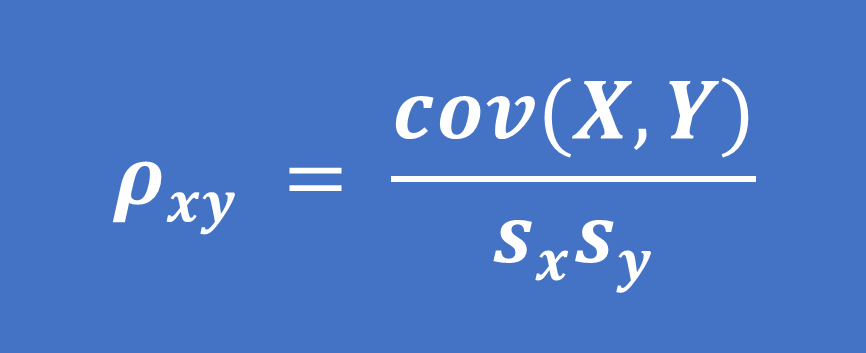 (4)
(4)
Trong đó: cov(X,Y) là hiệp phương sai của 2 biến ngẫu nhiên X,Y
σx , σy là độ lệch chuẩn của tổng thể
sx , sy là độ lệch chuẩn của mẫu
– Trực quan bằng đồ thị: (Business Analytics, 2017)
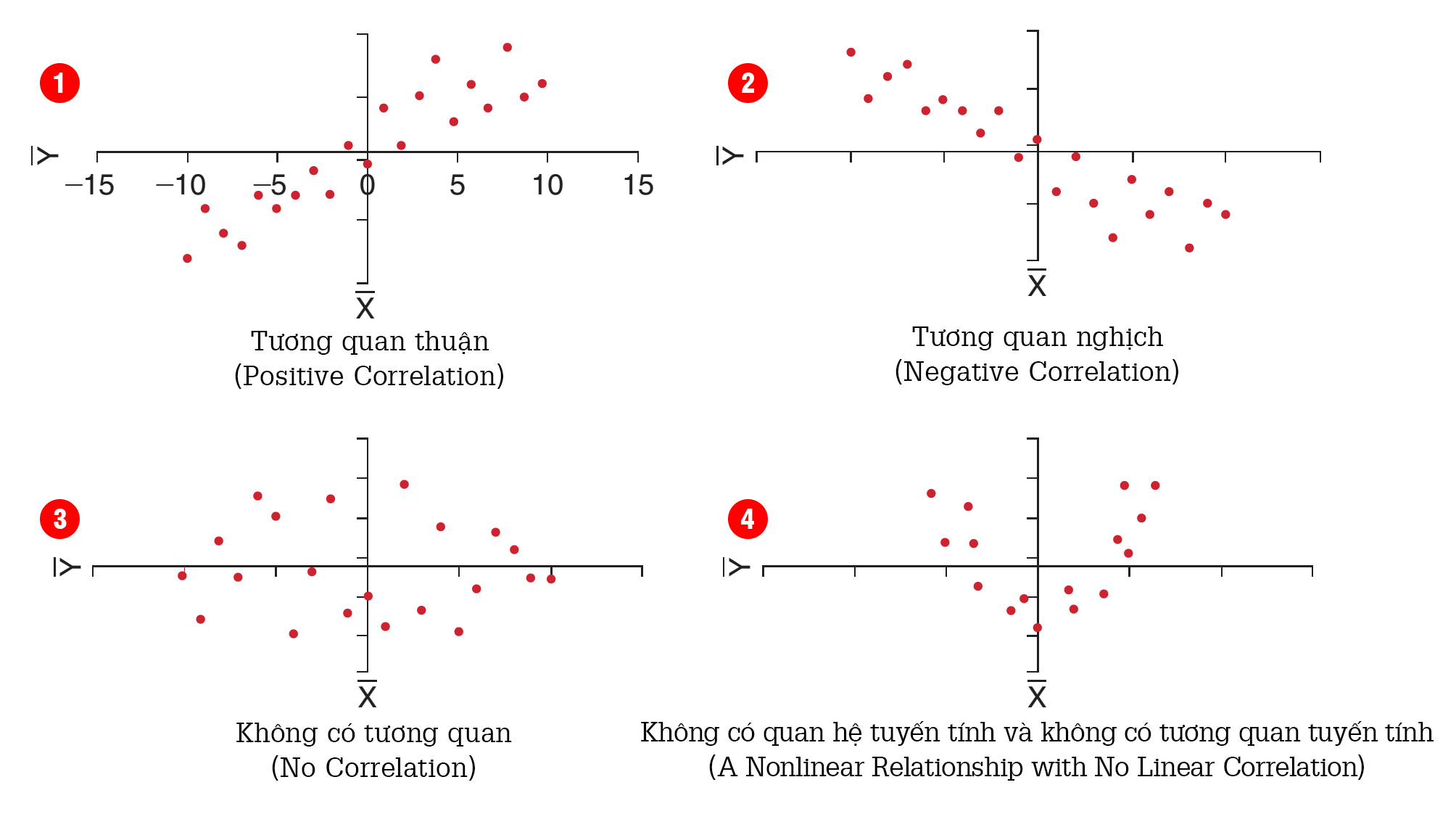
Đồ thị cho biết 4 trường hợp xảy ra khi tính hệ số tương quan Pearson:
- 2 biến X và Y có quan hệ tuyến tính thuận với nhau, ρxy >0, X tăng, Y tăng.
- 2 biến X và Y có quan hệ tuyến tính nghịch với nhau, ρxy <0, X tăng, Y giảm và ngược lại.
- và 4. Khi ρxy =0, 2 biến X và Y có thể không có mối quan hệ với nhau hoặc có mối quan hệ rõ ràng giữa các biến nhưng mối quan hệ này không tuyến tính và cũng không có tương quan.
– Ví dụ: Trong dữ liệu quan hệ giữa chiều cao (cm) và cân nặng (kg) ở ví dụ trên
Hcm= {162, 165, 168} Wkg = {50, 56, 60}
Ta có: ρ(Hcm, Wkg) = 0,9933
Khi thay đổi đơn vị: chiều cao (cm ->inch) và cân nặng (kg ->lb)
Hinch = Hcm/2,54 Wlb = Wkgx 2,2
Ta có: ρ(Hinch, Wlb) = 0,9933
Kết quả tính toán hệ số tương quan cho thấy chiều cao và cân nặng có mối tương quan thuận rất mạnh. Với việc chuẩn hóa giá trị trong khoảng [–1;1] nên khi đổi đơn vị đo lường thì kết quả hệ số tương quan vẫn giống nhau.
– Ma trận tương quan (Correlation matrix)
Cũng giống với ma trận hiệp phương sai, ma trận tương quan là một bảng thể hiện hệ số tương quan giữa các biến khi ta có nhiều hơn 2 biến trong bộ dữ liệu. Mỗi ô trong bảng hiển thị mối tương quan giữa hai biến. Ma trận tương quan thường được sử dụng trước hoặc sau khi thực hiện phân tích nhân tố khám phá (Exploratory Factor Analysis – EFA) để xem xét mối tương quan giữa các nhân tố và dùng để chẩn đoán hiện tượng đa cộng tuyến[4] trong mô hình hồi quy tuyến tính đa biến. Tuy nhiên, việc chẩn đoán đa cộng tuyến cũng mang tính tương đối, do các biến có thể có đa cộng tuyến ngay cả khi không có tương quan lớn.
– Ví dụ: ma trận tương quan giữa biến HV và 6 biến khác có ký hiệu lần lượt NL, GV, TD, DK, HQ, AH được cho trong bảng dưới đây. Trong đó, giả thuyết của nghiên cứu này là 6 biến (NL, GV, TD, DK, HQ, AH) có ảnh hưởng đến biến HV trong mô hình hồi quy tuyến tính đa biến.
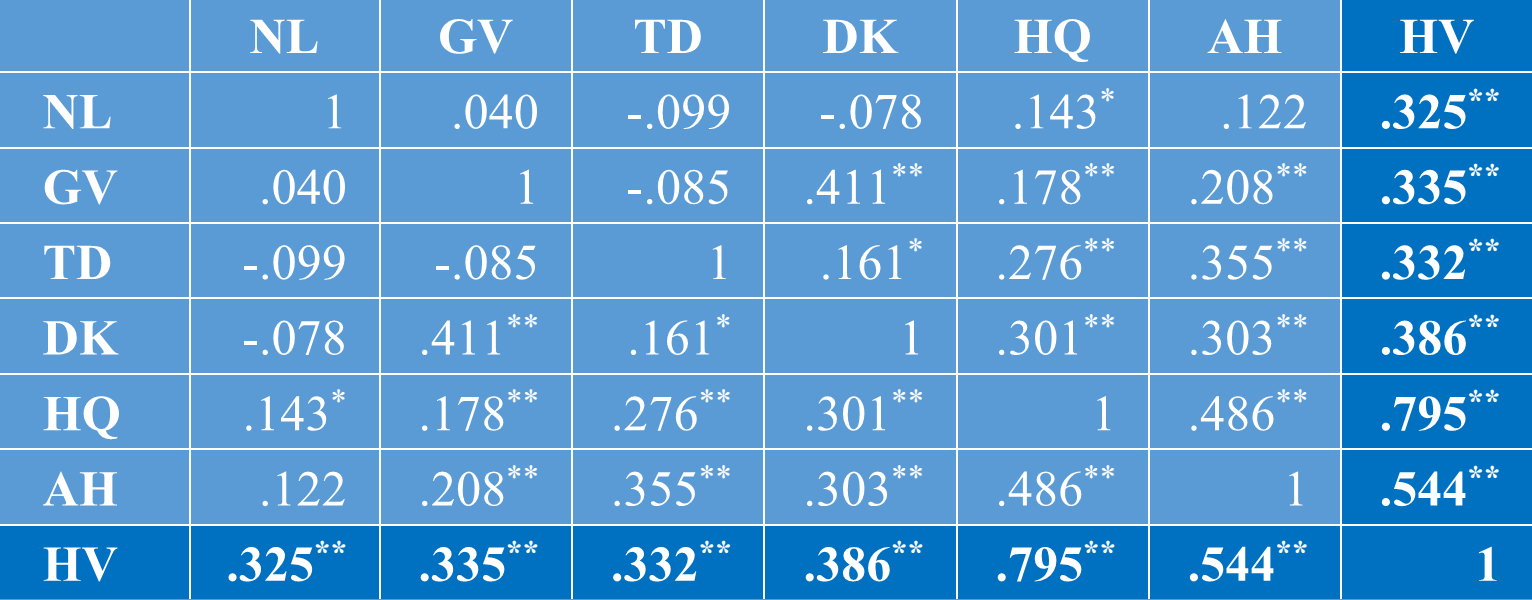
Ghi chú: * Tương quan có ý nghĩa tại giá trị Sig=0.05, ** Tương quan có ý nghĩa tại giá trị Sig=0.01
Hệ số tương quan giữa biến HV và các 6 biến (NL, GV, TD, DK, HQ, AH) lớn chứng tỏ giữa chúng có mối quan hệ với nhau và phân tích hồi quy tuyến tính có thể phù hợp. Tuy nhiên, giữa các biến độc lập cũng có tương quan lớn với nhau thì đó cũng là dấu hiệu cho biết giữa chúng có thể xảy ra hiện tượng đa cộng tuyến.
– Lưu ý:
- Hệ số tương quan Pearson sử dụng với biến định lượng và có thể dùng cho dữ liệu khác thang đo.
- Sự hiện diện của một mối tương quan giữa 2 biến không đủ để suy ra sự hiện diện của mối quan hệ nhân quả. Chẳng hạn như trong ma trận hệ số tương quan ở ví dụ trên, hệ số tương quan chỉ cho biết mối tương quan giữa các biến, không quyết định biến nào ảnh hưởng, biến nào không ảnh hưởng lên biến phụ thuộc HV. Do đó, muốn xác định quan hệ nhân quả, cần có phân tích nâng cao hơn như hồi quy tuyến tính.
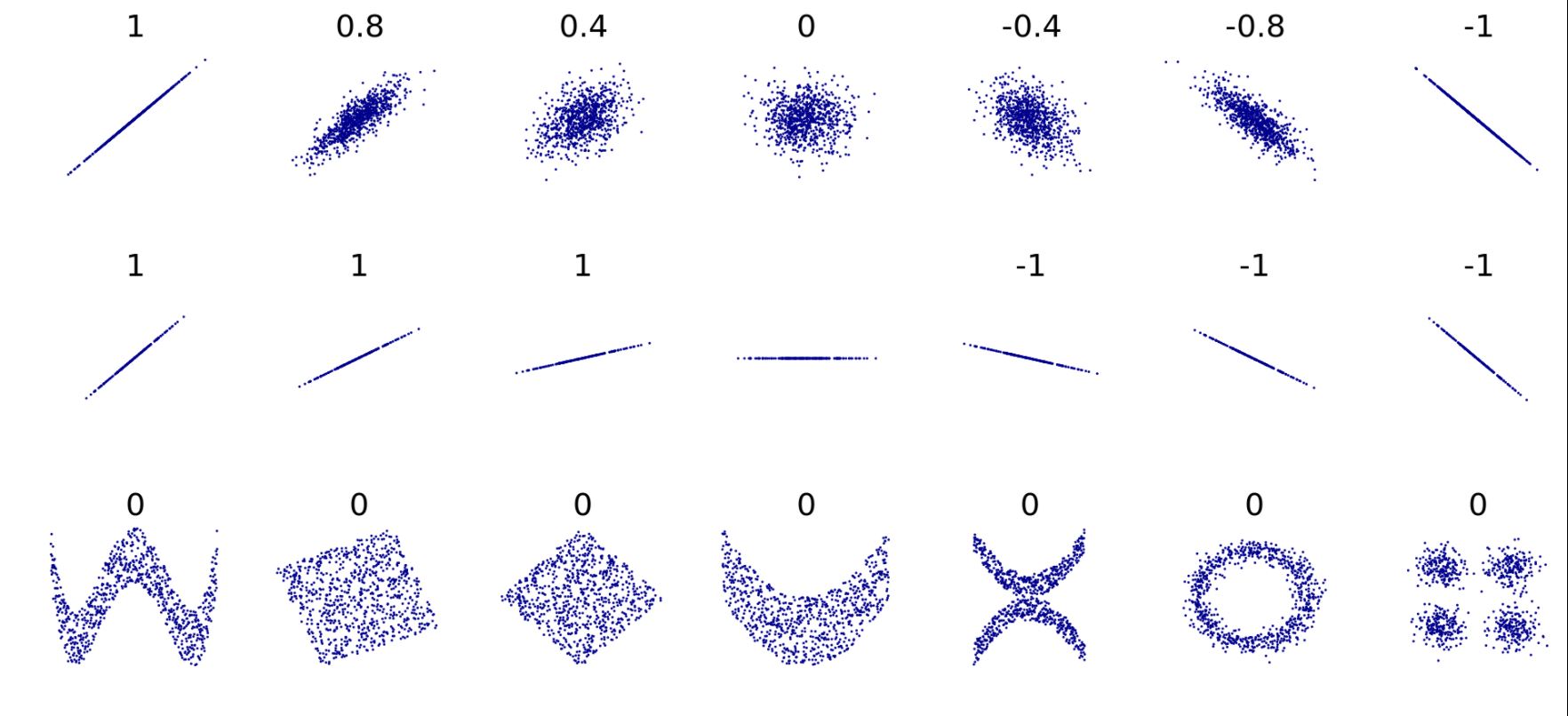
- Nhiều trường hợp xảy ra mối quan hệ phi tuyến tính khi kết hợp tính toán hệ số tương quan Pearson với trực quan dữ liệu bằng biểu đồ như hình dưới đây: Trong hàng đầu tiên, mối tương quan phản ánh mức độ phân tán và xu hướng của mối quan hệ tuyến tính; nhưng không phản ánh độ dốc của mối quan hệ đó (hàng giữa), cũng như mối quan hệ phi tuyến tính của các biến (hàng dưới cùng). (Wikipedia, 2021). Do đó, với 2 biến X,Y độc lập, ta có thể suy ra hệ số tương quan ρxy=0; tuy nhiên điều ngược lại có thể không đúng.
3. Hệ số tương quan Spearman (Spearman rank correlation)
Hệ số tương quan Spearman (Spearman rank correlation), thường được ký hiệu ρ hay rs (bài viết này sử dụng ký hiệu là rs để tránh trùng với ký hiệu của hệ số tương quan Pearson) là thước đo phi tham số về tương quan thứ hạng (sự phụ thuộc thống kê giữa thứ hạng của hai biến). Nó đánh giá mối quan hệ giữa hai biến có thể được mô tả tốt như thế nào bằng cách sử dụng một hàm đơn điệu[5]. Hệ số tương quan Spearman còn được định nghĩa là hệ số tương quan Pearson giữa các biến thứ hạng (Myers et. al, 2003).
– Công thức tính hệ số tương quan Spearman:
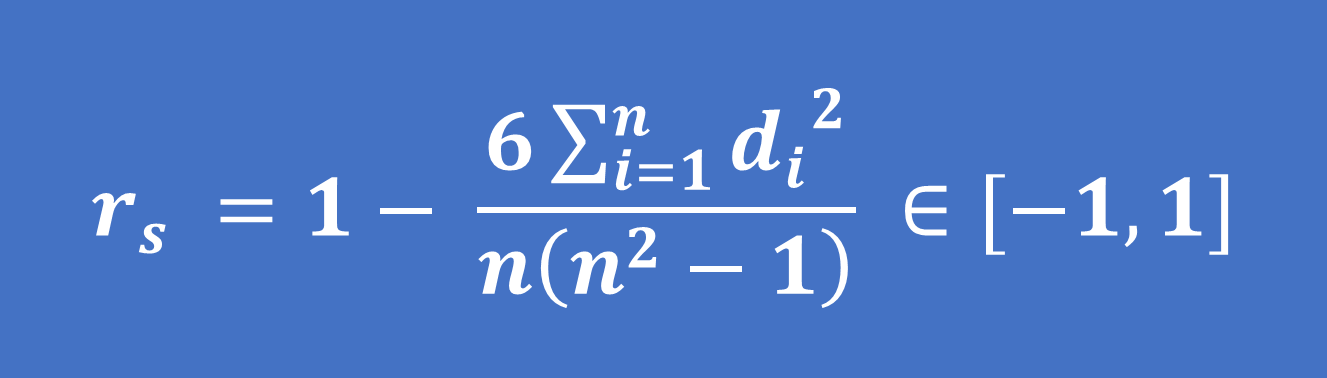 (5)
(5)
Trong đó: di= rank(xi) – rank(yi) là độ lệch giữa 2 thứ hạng tương ứng với mỗi quan sát của 2 biến X,Y
n là tổng số quan sát của 2 biến X,Y
– Trực quan bằng đồ thị: (Wikipedia, 2021)
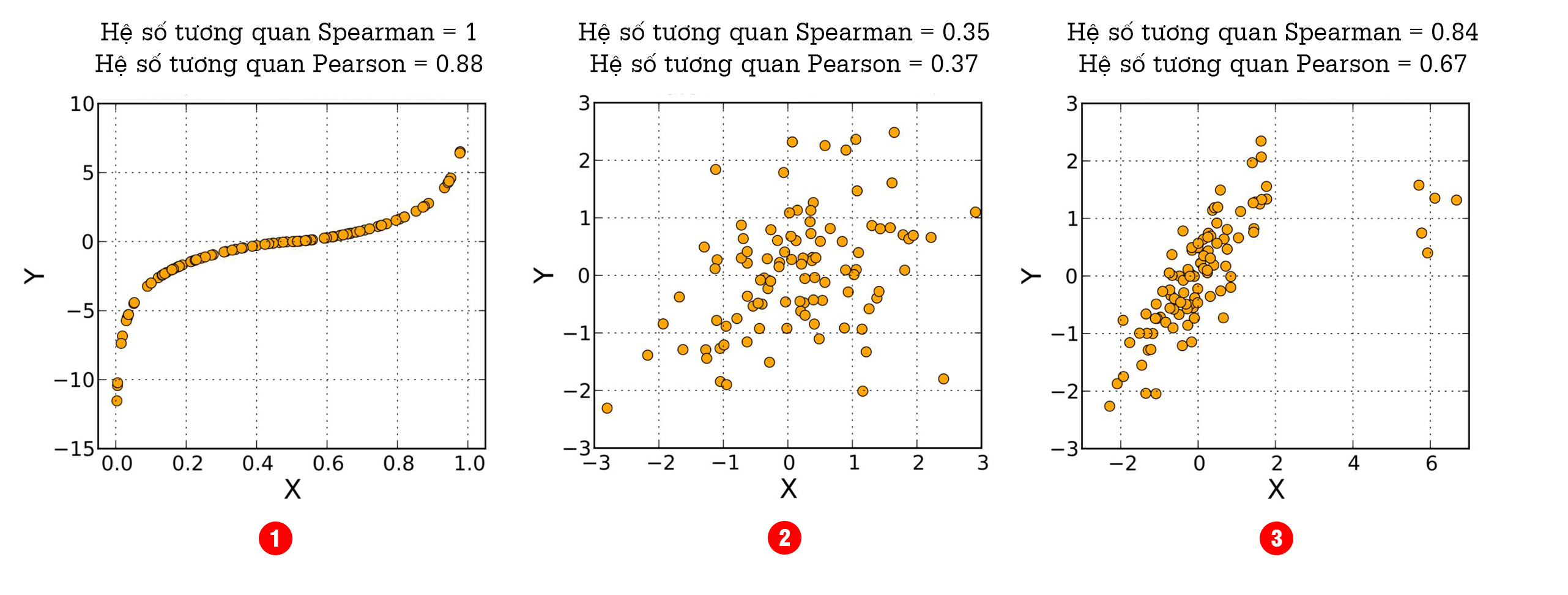
Đồ thị trên cho thấy sự so sánh giữa 2 hệ số tương quan Pearson và Spearman trong 3 trường hợp:
- Hệ số tương quan Spearman rs =1, tương quan hạng rất cao, ngay cả khi mối quan hệ của chúng không tuyến tính. Biểu đồ cho thấy 2 biến X và Y có quan hệ đơn điệu với nhau, có nghĩa là tất cả các điểm dữ liệu có giá trị x lớn hơn giá trị của một điểm dữ liệu nhất định cũng sẽ có giá trị y lớn hơn. Trong trường hợp này, hệ số tương quan Pearson lại không đưa ra được kết quả tương quan tối ưu (ρxy =0,88).
- Hệ số tương quan Spearman rs =0.35, dữ liệu được phân phối giống hình elip và 2 biến X,Y không có giá trị ngoại lệ nào nổi bật. Lúc này, hệ số tương quan Spearman và hệ số tương quan Pearson cho các giá trị xấp xỉ gần bằng nhau (ρxy =0,88).
- Hệ số tương quan Spearman rs =0.84, dữ liệu của 2 biến X,Y có các giá trị ngoại lệ xuất hiện khá nổi bật. Trong trường hợp này, hệ số tương quan Pearson tối ưu hơn do hệ số Spearman đã giới hạn các giá trị ngoại lệ bằng thứ hạng của nó.
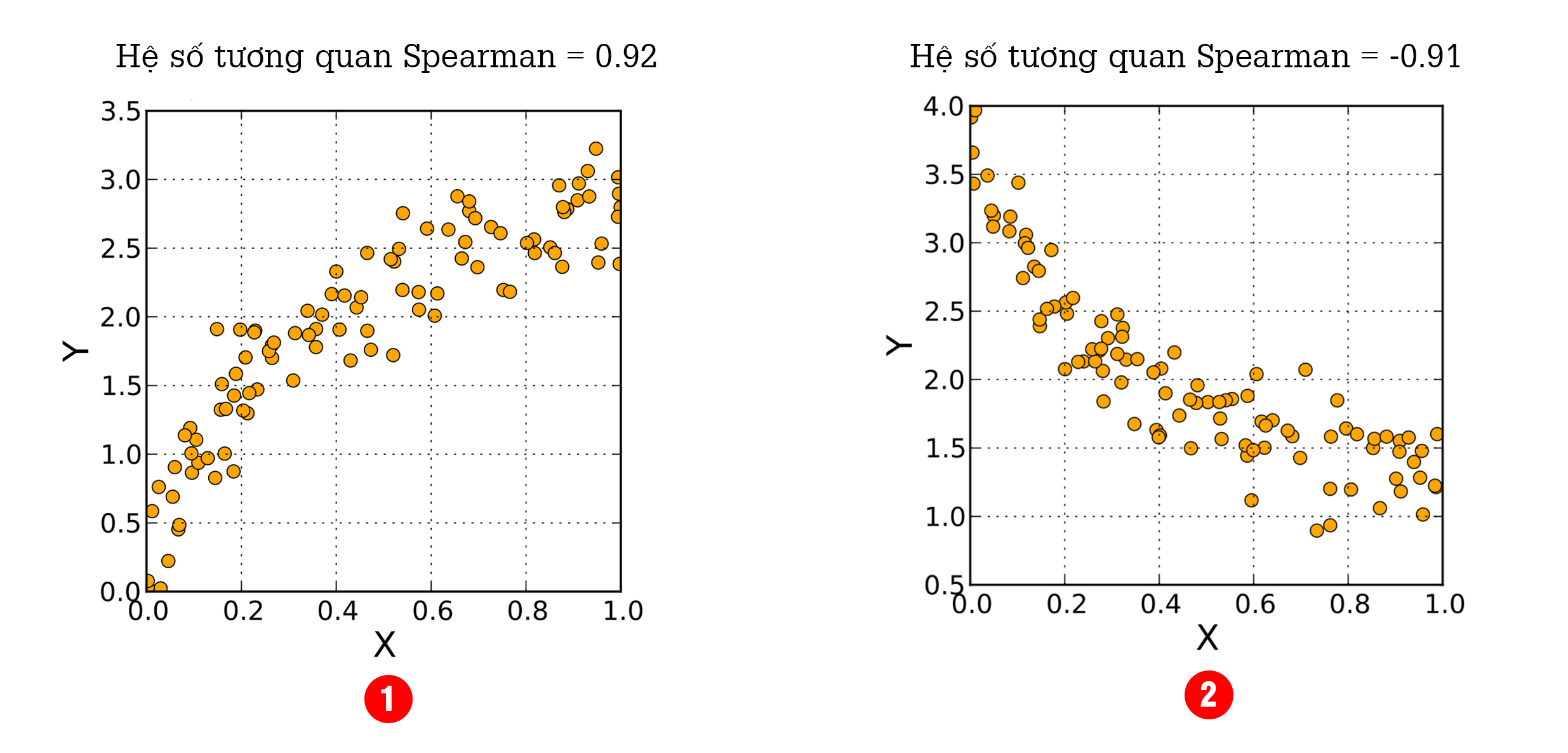
Đồ thị trên cho thấy 2 trường hợp tương quan Spearman thuận và nghịch
- Hệ số tương quan Spearman giữa hai biến sẽ thuận chiều khi xu hướng đơn điệu giữa các quan sát trong biến X và Y cùng tăng
- Hệ số tương quan Spearman giữa hai biến sẽ nghịch chiều khi xu hướng đơn điệu giữa các quan sát trong biến X và Y tăng giảm ngược chiều.
– Tính toán hệ số tương quan Spearman khi có 2 hay nhiều quan sát có cùng thứ hạng
Trong trường hợp các quan sát trong 2 biến X và Y không có quan sát nào đồng hạng với nhau, ta có thể tính hệ số tương quan Spearman dễ dàng theo công thức (5)
Ví dụ: Cho bảng sau có 9 quan sát của 2 biến X và Y:
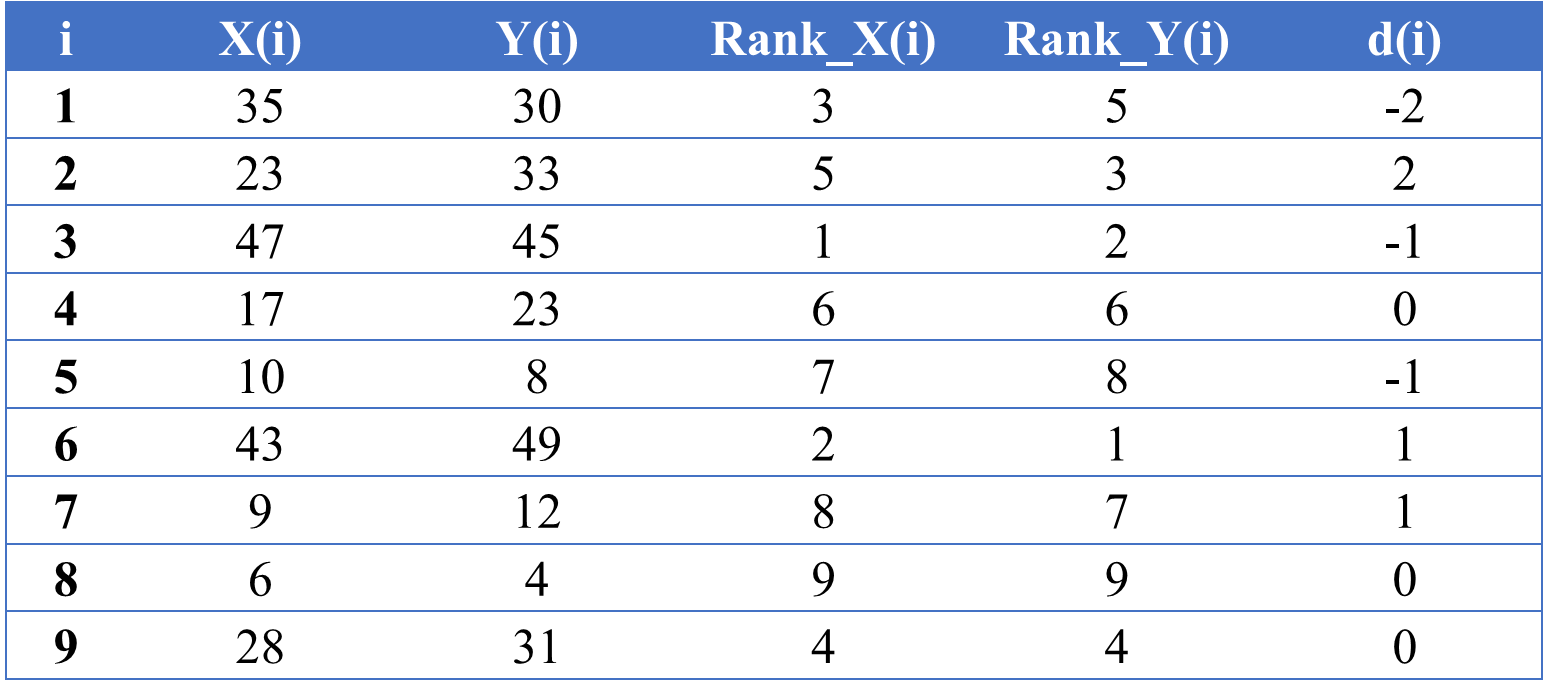
Áp dụng công thức tính hệ số tương quan (5), ta tính được rs = 0,9
Trường hợp trong 2 biến X và Y có các quan sát đồng hạng với nhau, còn được gọi là thứ hạng ràng buộc (tied ranks), ta thực hiện các bước như sau:
- Xếp hạng các thứ hạng bị ràng buộc như thể chúng không bị ràng buộc
- Cộng tất cả các thứ hạng đó lại với nhau và chia cho tổng số quan sát có thứ hạng ràng buộc
- Tính hệ số tương quan Spearman theo công thức (5)
Ví dụ: Cho bảng sau có 9 quan sát của 2 biến X và Y, trong đó Y có 2 quan sát có cùng hạng
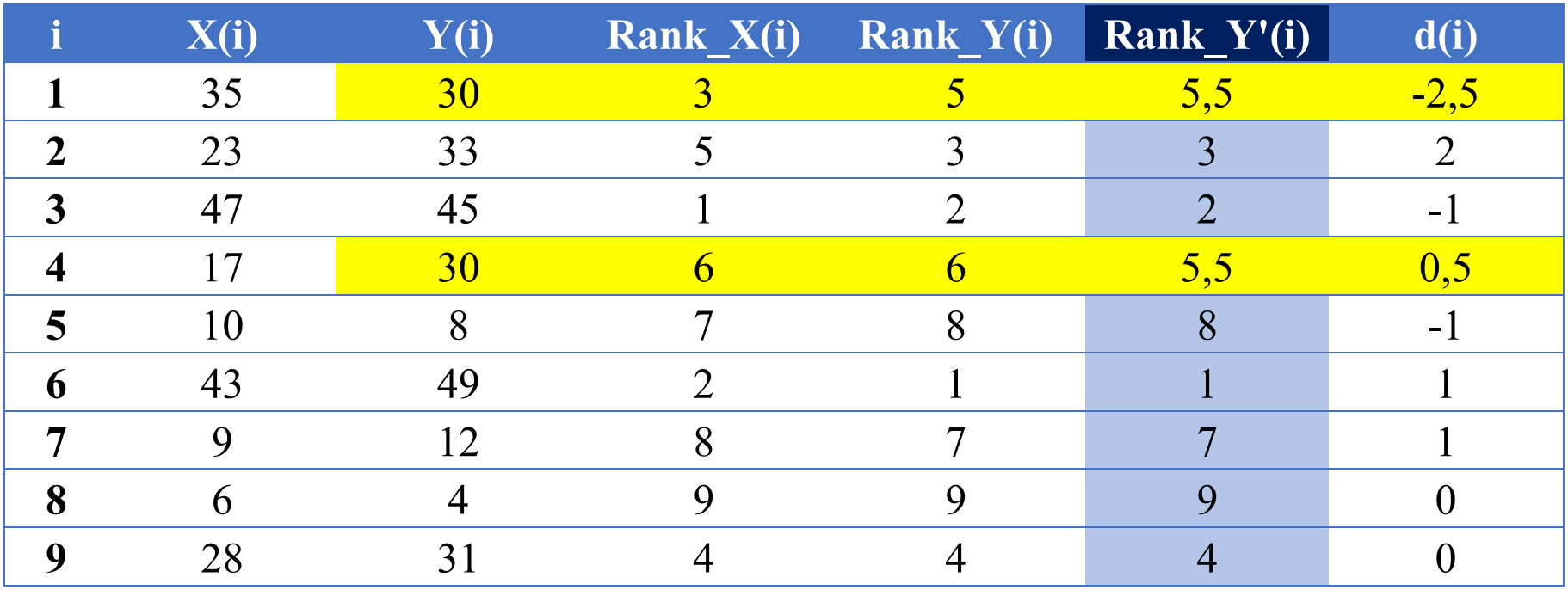
Áp dụng công thức tính hệ số tương quan (5), ta tính được rs = 0,88
Duy Sang tổng hợp
----------------------------------------
Tài liệu tham khảo:
– Agresti A., Franklin C. (2013). Exploring Data with Graphs and Numerical Summaries. In F. C. Agresti A., Statistics: The Art and Science of Learning from Data (pp. 23-88). Pearson.
– Evans, J. R. (2017). Business Analytics. Pearson.
– Illowsky et al. (2013). Introductory Statistics. Houston: OpenStax.
– Wikipedia. (2021, August 3). Correlation. Retrieved from Wikipedia: https://en.wikipedia.org/wiki/Correlation
– Wikipedia. (2021, May 30). Covariance. Retrieved from Wikipedia: https://en.wikipedia.org/wiki/Covariance
– Wikipedia. (2021, August 2). Spearman's rank correlation coefficient. Retrieved from Wikipedia: https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient
– Wilke, C. O. (2019). Fundamentals of Data Visualization. O’Reilly Media.
----------------------------------------
Các bài viết liên quan:
Thống kê mô tả trong nghiên cứu – Các đại lượng về trung tâm
Thống kê mô tả trong nghiên cứu – Các đại lượng về độ phân tán
Thống kê mô tả trong nghiên cứu – Các đại lượng về hình dáng phân phối
---------------------------------------------------------------------------------------------------